Lektion 1: Die Revolution der künstlichen Stimme
Noch vor wenigen Jahren klangen computergenerierte Stimmen roboterhaft und unnatürlich. Wer einen Sprachassistenten nutzte, erkannte sofort, dass eine Maschine sprach. Diese Zeiten sind vorbei. Die neueste Generation von Text-to-Speech-Systemen erzeugt Stimmen, die von menschlichen Sprechern kaum noch zu unterscheiden sind — mit natürlichen Pausen, emotionalen Nuancen und sogar regionalen Akzenten.
Der technologische Durchbruch basiert auf neuronalen Netzwerken, die nicht mehr einzelne Laute zusammensetzen, sondern ganze Sprachmelodien erlernen. Modelle wie ElevenLabs, OpenAI TTS oder Googles WaveNet analysieren hunderte Stunden menschlicher Sprache und erfassen dabei nicht nur die Aussprache, sondern auch Rhythmus, Betonung und emotionale Färbung. Das Ergebnis sind Stimmen, die fliessend vorlesen, Fragen mit der richtigen Intonation stellen und sogar lachen oder zöigern können.
Für Unternehmen eröffnet das völlig neue Möglichkeiten. Ein E-Commerce-Händler in Berlin nutzt Voice AI, um seine Produktbeschreibungen als Audio-Variante anzubieten. Kunden, die unterwegs sind oder eine Sehbehinderung haben, können sich Produktinformationen vorlesen lassen — in einer angenehmen, natürlich klingenden Stimme, die zur Markenidentität passt. Die Conversion-Rate bei Nutzern, die den Audio-Modus verwenden, liegt 15 Prozent über dem Durchschnitt, weil die persönliche Ansprache Vertrauen schafft.
Der Markt für Voice AI wächst rasant. Analysten schätzen das globale Marktvolumen für 2026 auf über 30 Milliarden Dollar, getrieben von Anwendungen im Kundenservice, in der Content-Produktion und in der Barrierefreiheit. Wer heute in Voice-Kompetenz investiert, verschafft sich einen Vorsprung in einem Markt, der gerade erst beginnt, sein Potenzial zu entfalten.
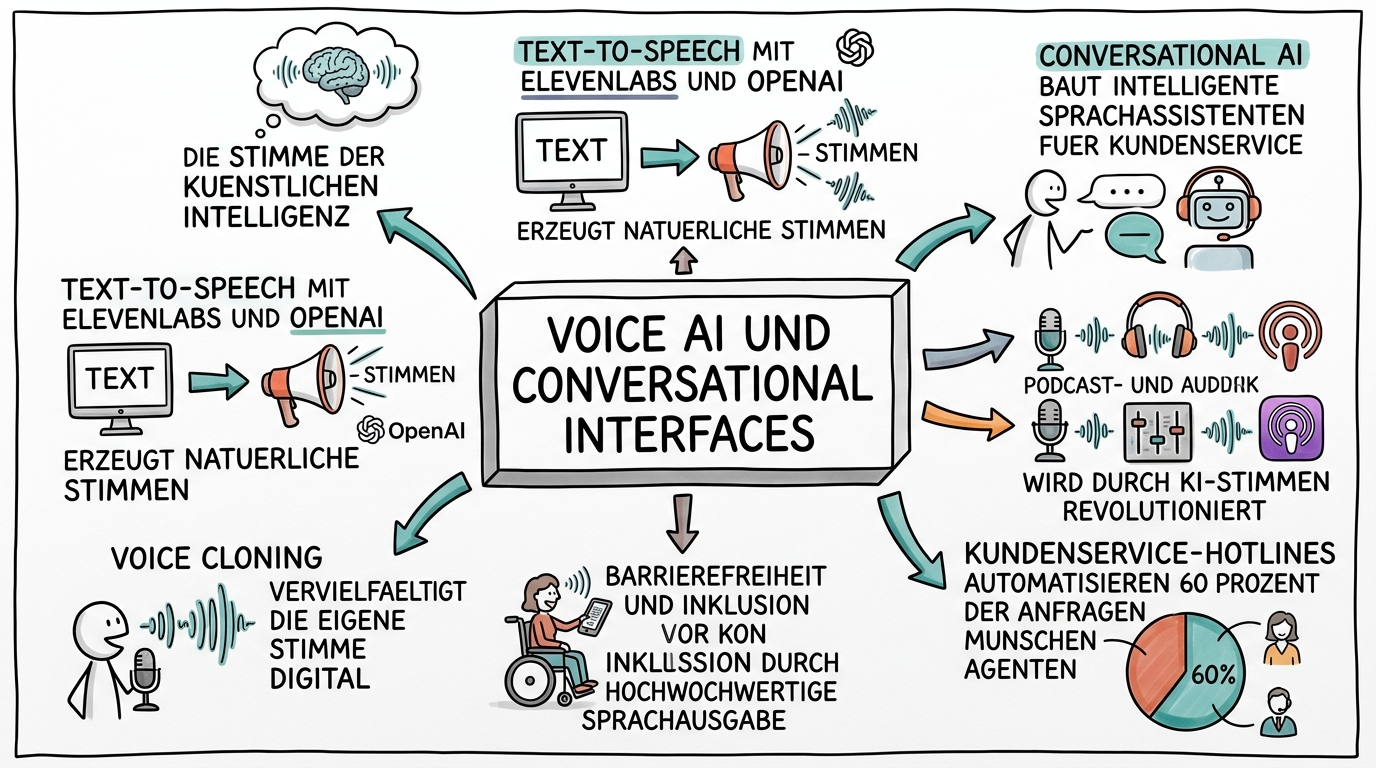
Lektion 2: Text-to-Speech — Technik, Tools und praktischer Einsatz
Text-to-Speech, kurz TTS, wandelt geschriebenen Text in gesprochene Sprache um. Was simpel klingt, ist technisch hochkomplex: Ein gutes TTS-System muss Homographe unterscheiden (liest sie den Text oder liest er gern?), Abkürzungen korrekt aussprechen, Zahlen kontextabhängig interpretieren und die richtige Satzmelodie wählen. Die führenden Anbieter haben diese Herausforderungen weitgehend gelöst.
ElevenLabs hat sich als Marktführer für hochwertige Sprachsynthese etabliert. Die Plattform bietet über 30 vortrainierte Stimmen in dutzenden Sprachen und erlaubt die Feinsteuerung von Parametern wie Stabilität, Klarheit und Emotionalität. Besonders beeindruckend ist die Geschwindigkeit: Ein Blogartikel mit 2.000 Wörtern wird in unter 10 Sekunden in eine natürlich klingende Audiodatei umgewandelt. Die Kosten liegen je nach Tarif zwischen 5 und 100 Dollar pro Monat, was TTS auch für kleine Unternehmen und Solopreneure erschwinglich macht.
OpenAI bietet mit seiner TTS-API eine entwicklerfreundliche Alternative. Sechs Stimmen stehen zur Verfügung, die sich durch ihre Natürlichkeit auszeichnen, auch wenn sie weniger Anpassungsmöglichkeiten als ElevenLabs bieten. Der grosse Vorteil liegt in der nahtlosen Integration mit anderen OpenAI-Diensten: Ein Workflow kann einen Text mit GPT-4 generieren lassen und ihn im nächsten Schritt automatisch vertonen. Für Unternehmen, die bereits die OpenAI-API nutzen, ist das der einfachste Einstieg in Voice AI.
Ein Bildungsverlag in München hat TTS in seine digitale Lernplattform integriert. Sämtliche Lehrtexte sind jetzt auch als Audio verfügbar, gesprochen von einer KI-Stimme, die speziell für pädagogische Inhalte optimiert wurde. Die Rückmeldungen der Lernenden sind überwiegend positiv: Besonders geschätzt wird die Möglichkeit, die Vorlesegeschwindigkeit anzupassen und zwischen verschiedenen Stimmen zu wechseln, um die Aufmerksamkeit hochzuhalten.
Lektion 3: Voice Cloning — die eigene Stimme digital vervielfältigen
Voice Cloning gehört zu den faszinierendsten und zugleich umstrittensten Anwendungen der Voice AI. Mit nur wenigen Minuten Audiomaterial kann ein KI-System eine Stimme so präzise nachbilden, dass selbst enge Vertraute den Unterschied kaum bemerken. Diese Technologie eröffnet enorme Chancen für Content-Ersteller, birgt aber auch erhebliche Risiken, die verantwortungsvoll gemanagt werden müssen.
Die technische Funktionsweise basiert auf einem zweistufigen Prozess. Zunächst analysiert das System die Stimmcharakteristik anhand des bereitgestellten Audiomaterials: Tonhöhe, Sprechrhythmus, Artikulation und Klangfarbe werden als mathematisches Modell erfasst. Anschliessend kann dieses Modell beliebige Texte in der geklonten Stimme wiedergeben. ElevenLabs benötigt dafür minimal eine Minute hochwertiges Audio, empfiehlt aber 30 Minuten für optimale Ergebnisse. Die Qualität hat ein Niveau erreicht, bei dem professionelle Sprecher ihre eigenen Klone nicht zuverlässig identifizieren können.
Für Unternehmen bietet Voice Cloning handfeste Vorteile. Eine Unternehmensberaterin aus Frankfurt hat ihre Stimme klonen lassen und nutzt den Klon, um Newsletter, Social-Media-Beiträge und Kursmodule zu vertonen. Statt jede Woche Stunden im Tonstudio zu verbringen, tippt sie ihren Text ein und erhält in Sekunden eine Audiodatei, die exakt wie sie klingt. Ihre Community schätzt die persönliche Note, und sie selbst spart rund zehn Stunden pro Monat. Ähnlich verfahren Podcast-Hosts, die Werbeeinspieler in ihrer eigenen Stimme generieren, oder CEOs, die interne Updates als persönliche Sprachnachricht versenden.
Die ethische Dimension darf nicht unterschätzt werden. Voice Cloning ohne Einwilligung ist in der EU durch die DSGVO und den EU AI Act streng reguliert. Seriose Anbieter wie ElevenLabs verlangen eine verifizierte Einwilligung des Stimmgebers und kennzeichnen geklonte Stimmen mit einem unsichtbaren Wasserzeichen. Unternehmen sollten interne Richtlinien etablieren: Wessen Stimme darf geklont werden, für welche Zwecke, und wie wird die Einwilligung dokumentiert? Transparenz gegenüber Zuhörinnen und Zuhörern gehört ebenfalls dazu — ein einfacher Hinweis wie "Dieser Beitrag wurde mit KI-Sprachsynthese erstellt" genügt in den meisten Fällen.
Lektion 4: Conversational AI — intelligente Sprachassistenten bauen
Conversational AI bezeichnet Systeme, die natürliche Gespräche mit Menschen führen können. Im Unterschied zu einfachen Chatbots, die auf vordefinierte Frage-Antwort-Paare zurückgreifen, verstehen Conversational-AI-Systeme den Kontext eines Gesprächs, erinnern sich an frühere Aussagen und reagieren flexibel auf unerwartete Wendungen. Die Kombination aus Spracherkennung, Sprachverständnis und Sprachsynthese ermöglicht erstmals telefon- und sprachbasierte KI-Assistenten, die echten Mehrwert liefern.
Die Architektur eines modernen Sprachassistenten besteht aus drei Schichten. Die erste Schicht — Automatic Speech Recognition, ASR — wandelt gesprochene Sprache in Text um. Dienste wie Whisper von OpenAI oder Googles Speech-to-Text erreichen hier Fehlerquoten unter 5 Prozent, selbst bei Dialekten und Hintergrundgeräuschen. Die zweite Schicht — Natural Language Understanding, NLU — interpretiert den Text und erkennt die Absicht des Sprechers. Die dritte Schicht generiert eine passende Antwort und wandelt sie per TTS wieder in Sprache um. Der gesamte Prozess dauert heute unter einer Sekunde, was natürliche Gespräche in Echtzeit ermöglicht.
Ein Energieversorger aus Norddeutschland hat einen KI-Sprachassistenten für seine Kunden-Hotline eingeführt. Der Assistent bearbeitet Standardanfragen wie Zählerstandsmeldungen, Tarifauskünfte und Umzugsmitteilungen vollständig autonom. Bei komplexen Anliegen — etwa einer Beschwerde oder einem technischen Notfall — übergibt er das Gespräch nahtlos an einen menschlichen Mitarbeiter und fasst dabei den bisherigen Gesprächsverlauf zusammen. Nach sechs Monaten bearbeitet der Assistent 62 Prozent aller Anrufe ohne menschliches Eingreifen, während die durchschnittliche Wartezeit für Kunden von vier Minuten auf unter 30 Sekunden gesunken ist.
Für den Aufbau eines eigenen Conversational-AI-Systems stehen verschiedene Plattformen zur Verfügung. Voiceflow bietet eine visülle Entwicklungsumgebung, in der auch Nicht-Programmierer komplexe Gesprächsverläufe gestalten können. Amazon Lex und Google Dialogflow richten sich an Entwicklerteams, die tiefere Integration in bestehende Systeme benötigen. Die Wahl hängt vom Anwendungsfall ab: Für einen einfachen FAQ-Assistenten reicht Voiceflow, für eine vollintegrierte Kundenservice-Lösung mit CRM-Anbindung sind die Cloud-Plattformen die bessere Wahl.
Lektion 5: Voice AI im Kundenservice — Best Practices und Fallstricke
Der Kundenservice ist das Anwendungsfeld, in dem Voice AI den grössten unmittelbaren Business-Impact entfaltet. Die Kombination aus 24/7-Verfügbarkeit, sofortiger Reaktion und gleichbleibender Qualität adressiert drei der grössten Herausforderungen im Service: Wartezeiten, Personalengpässe und inkonsistente Beratungsqualität. Doch der Weg zur erfolgreichen Implementierung ist voller Fallstricke.
Der wichtigste Erfolgsfaktor ist die richtige Abgrenzung zwischen KI und Mensch. Nicht jedes Anliegen eignet sich für einen KI-Assistenten. Faustregel: Alles, was strukturiert, wiederholbar und regelbasiert ist, kann die KI übernehmen. Alles, was Empathie, Kreativität oder Eskalationsmanagement erfordert, bleibt beim Menschen. Ein Online-Händler, der seinen Retourenprozess komplett an eine KI delegierte, erlebte einen Anstieg der Kundenbeschwerden um 40 Prozent — weil Kunden bei emotionalen Anliegen wie beschädigter Ware oder verspäteten Geschenken auf eine kalte Maschine trafen, die ihr Ärger nicht interessierte.
Die Gestaltung der Stimme ist ein unterschätzter Erfolgsfaktor. Studien zeigen, dass Kunden auf warme, mittlere Stimmlagen positiver reagieren als auf hohe oder tiefe Stimmen. Die Sprechgeschwindigkeit sollte etwas langsamer sein als im normalen Gespräch, und Pausen nach wichtigen Informationen geben dem Kunden Zeit zum Verarbeiten. Einige Unternehmen lassen ihre KI-Stimme bewusst "menschliche" Eigenheiten einbauen — ein leises "Moment" beim Nachschlagen oder ein "Das verstehe ich" vor der eigentlichen Antwort — um die Interaktion natürlicher wirken zu lassen.
Für die Qualitätssicherung empfiehlt sich ein kontinuierliches Monitoring-System. Analysieren Sie regelmässig, bei welchen Anliegen die KI an ihre Grenzen stösst, wo Kunden das Gespräch abbrechen und wie sich die Kundenzufriedenheit im Vergleich zum menschlichen Service entwickelt. Ein Dashboard, das diese Metriken in Echtzeit anzeigt, ermöglicht schnelle Korrekturen. Planen Sie ausserdem regelmässige Reviews ein, bei denen sich menschliche Agenten Gesprächsprotokolle der KI anhören und Verbesserungsvorschläge einbringen.
Lektion 6: Podcasts, Audiobooks und Content-Produktion mit Voice AI
Voice AI transformiert nicht nur den Kundenservice, sondern auch die Content-Produktion. Podcasts, Hörbücher, Audiokurse und Sprachnewsletter lassen sich mit KI-Stimmen in einem Bruchteil der bisherigen Zeit und Kosten produzieren. Für Content-Ersteller, die bisher vor dem Aufwand einer Audio-Produktion zurückschreckten, senkt das die Einstiegshürde dramatisch.
Die Podcast-Produktion mit Voice AI beginnt mit einem gut geschriebenen Skript. Anders als beim freien Sprechen, wo natürliche Pausen und Füllwörter für Authentizität sorgen, muss ein KI-verlesenes Skript diese Elemente bewusst einbauen. Erfahrene Produzenten schreiben ihre Texte in einem gesprochenen Stil — mit kurzen Sätzen, direkter Ansprache und gelegentlichen rhetorischen Fragen — und fügen Regieanweisungen für Pausen und Betonungen hinzu. ElevenLabs unterstützt solche Anweisungen über SSML-Tags oder die Projektfunktion, mit der sich komplexe Audio-Produktionen mit mehreren Stimmen und Szenen steuern lassen.
Ein Wissensportal aus Österreich produziert täglich einen fünfminütigen Audio-Newsletter, der die wichtigsten Nachrichten aus der KI-Welt zusammenfasst. Das Redaktionsteam schreibt morgens den Text, die KI vertont ihn in drei Sprachen, und um 8 Uhr erscheint der Newsletter in den Podcast-Apps der Abonnenten. Die Produktionskosten für die Audio-Version liegen bei unter 50 Euro pro Monat — ein Bruchteil dessen, was ein menschlicher Sprecher kosten würde. Die Hörerzahlen haben sich seit der Einführung verdreifacht, weil viele Abonnenten den Newsletter jetzt auf dem Arbeitsweg konsumieren, statt ihn abends zu lesen.
Für Hörbücher und längere Formate ist die Qualitätskontrolle besonders wichtig. KI-Stimmen neigen bei längeren Texten gelegentlich zu Monotonie oder unnatürlichen Betonungen. Die Lösung liegt in der Nachbearbeitung: Ein Audio-Editor hört die Rohfassung gegen, markiert problematische Stellen und generiert diese Passagen mit angepassten Parametern neu. Dieser hybride Ansatz — KI-Produktion mit menschlicher Qualitätssicherung — liefert Ergebnisse, die für die meisten Anwendungsfälle völlig ausreichen und nur einen Bruchteil der traditionellen Produktion kosten.
Lektion 7: Barrierefreiheit und Inklusion durch Voice AI
Voice AI hat das Potenzial, digitale Inhalte für Millionen Menschen zugänglich zu machen, die bisher ausgeschlossen waren. Menschen mit Sehbehinderungen profitieren von hochwertiger Sprachausgabe, die weit über die monotonen Screenreader vergangener Jahre hinausgeht. Menschen mit motorischen Einschränkungen können per Sprache mit Systemen interagieren, statt Tastatur und Maus zu bemühen. Und Menschen mit Lese-Rechtschreib-Schwäche erhalten durch Audio-Alternativen einen gleichberechtigten Zugang zu Informationen.
Die EU-Richtlinie zur Barrierefreiheit, der European Accessibility Act, verpflichtet ab Juni 2025 viele Unternehmen, ihre digitalen Angebote barrierefrei zu gestalten. Voice AI bietet einen pragmatischen Weg zur Compliance. Statt jede Website und jede App komplett umzubauen, können Unternehmen ihre Inhalte als Audio-Alternative bereitstellen und ihre Interfaces um Sprachsteuerung ergänzen. Das ist nicht nur kostengünstiger, sondern verbessert auch die User Experience für alle Nutzer — denn Sprachsteuerung ist in vielen Situationen schlicht bequemer als Tippen.
Ein Beispiel aus der Praxis zeigt, wie wirkungsvoll dieser Ansatz sein kann. Eine Stadtverwaltung in Bayern hat ihre Bürgerservice-Website um einen KI-Sprachassistenten ergänzt, der Formulare erklärt, durch Anträge führt und Fragen in einfacher Sprache beantwortet. Ältere Bürgerinnen und Bürger, die mit der Navigation auf Websites Schwierigkeiten hatten, können nun per Telefon oder Sprachbefehl die gleichen Dienste nutzen wie digital-affine Jüngere. Die Zufriedenheit mit den Bürgerdiensten stieg messbar, und die Zahl der persönlichen Vorsprachen im Bürgeramt ging um 20 Prozent zurück.
Für die Implementierung barrierefreier Voice-Lösungen gelten besondere Anforderungen. Die Sprachausgabe muss langsam genug sein, um auch von Personen mit kognitiven Einschränkungen verstanden zu werden — idealerweise mit einstellbarer Geschwindigkeit. Die Spracherkennung muss mit undeutlicher Aussprache, Dialekten und Sprachstörungen zurechtkommen. Und das Gesamtsystem muss robust genug sein, um auch bei suboptimalen Bedingungen — laute Umgebung, schlechte Internetverbindung — zuverlässig zu funktionieren.