Synthetische Daten und KI-Datenstrategie
Lektion 1: Warum Daten das neue Gold der KI sind
Jedes KI-Modell ist nur so gut wie die Daten, mit denen es trainiert wurde. Diese Binsenweisheit hat in den letzten Jahren eine neue Dringlichkeit bekommen, denn die Welt steuert auf eine sogenannte "Data Wall" zu. Das frei verfügbare Internet als Trainingsquelle ist weitgehend ausgeschöpft, während gleichzeitig Datenschutzgesetze wie die DSGVO den Einsatz echter personenbezogener Daten immer stärker einschränken. Unternehmen stehen vor einem Dilemma: Sie brauchen mehr und bessere Daten für ihre KI-Projekte, dürfen aber immer weniger davon nutzen.
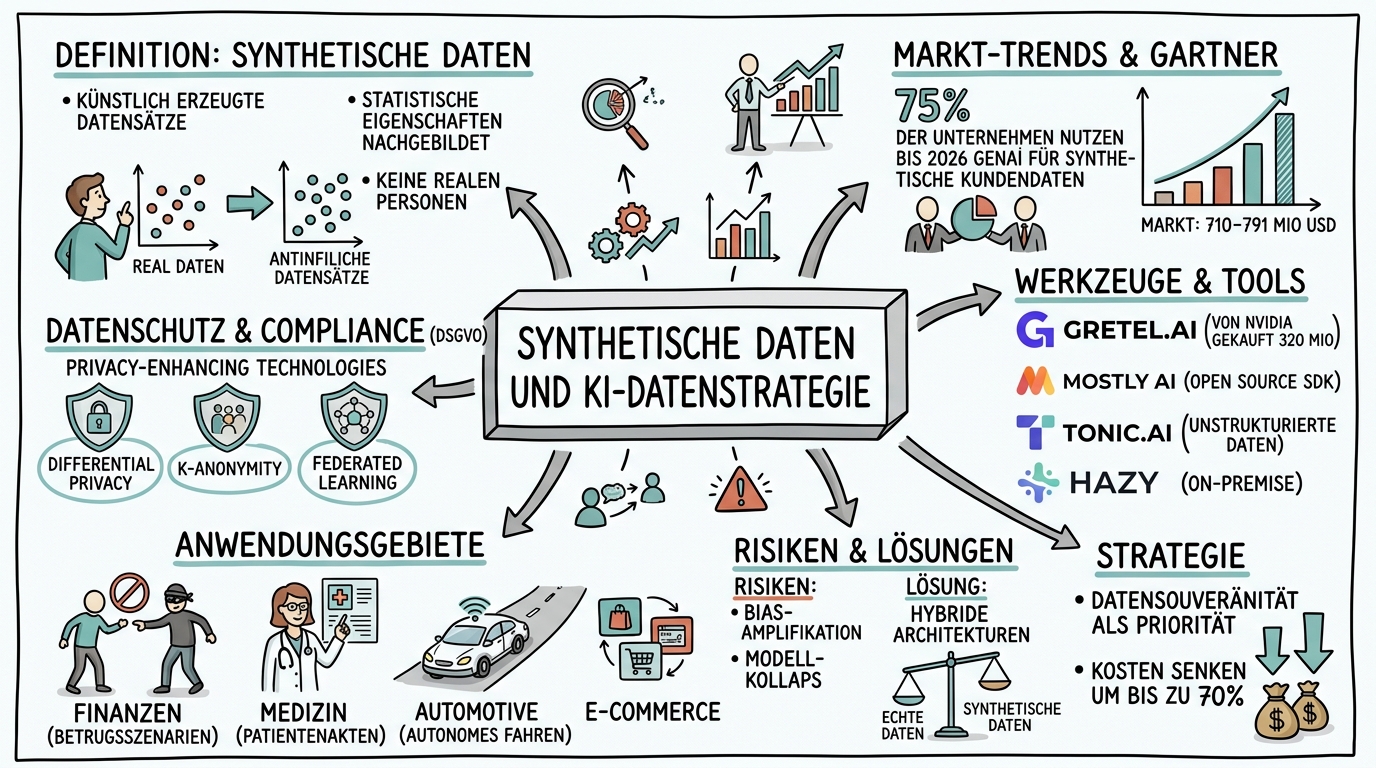
Die Lösung für dieses Problem heisst synthetische Daten. Dabei handelt es sich um künstlich erzeugte Datensätze, die die statistischen Eigenschaften echter Daten nachbilden, ohne tatsächliche Personen oder Ereignisse abzubilden. Laut Gartner werden bis 2026 rund 75 Prozent aller Unternehmen generative KI zur Erstellung synthetischer Kundendaten einsetzen. Noch bemerkenswerter ist die Prognose, dass bereits 2027 mehr KI-Modelle mit synthetischen als mit realen Daten trainiert werden. Der globale Markt für synthetische Datengenerierung wird 2026 auf rund 710 bis 791 Millionen US-Dollar geschätzt und wächst mit über 31 Prozent jährlich.
Die wirtschaftlichen Vorteile sind erheblich. Die Beschaffung und Bereinigung echter Daten ist oft teurer als die KI-Modelle selbst. Durch den Einsatz synthetischer Daten lassen sich datenbezogene Kosten um bis zu 70 Prozent senken. Noch wichtiger: Synthetische Daten lösen gleichzeitig Probleme des Datenschutzes, der Datenverfügbarkeit und der Datenqualität. Ein Finanzdienstleister kann beispielsweise tausende Betrugsszenarien simulieren, ohne auf echte Kundentransaktionen zurückgreifen zu müssen.
Lektion 2: Wie synthetische Daten entstehen
Die Erzeugung synthetischer Daten folgt einem dreistufigen Prozess: Zürst analysiert ein Modell die statistischen Verteilungen und Muster in einem realen Quelldatensatz. Dann generiert es neue Datenpunkte, die denselben Mustern folgen, aber keine echten Identifikatoren enthalten. Schliesslich wird die Qualität der erzeugten Daten anhand von Metriken wie Faithfulness, Relevance und Diversity validiert.
In der Praxis kommen verschiedene Technologien zum Einsatz. Generative Adversarial Networks, kurz GANs, trainieren zwei neuronale Netze gegeneinander: Ein Generator erzeugt synthetische Daten, während ein Diskriminator versucht, diese von echten Daten zu unterscheiden. Dieser Wettbewerb führt zu immer realistischeren Ergebnissen. Für tabellarische Daten haben sich spezialisierte Varianten wie CTGAN und TVAE etabliert. Bei Bilddaten kommen Modelle wie StyleGAN oder Stable Diffusion zum Einsatz, während Variational Autöncoders besonders für strukturierte Daten mit komplexen Abhängigkeiten geeignet sind.
Ein besonders spannendes Beispiel aus der Praxis zeigt IBM Technology in einem Tutorial: Mit Open-Source-Tools wie Docling für die Dokumentenverarbeitung und SDGHub für die Datenpipeline lässt sich eine vollständige synthetische Datengenerierung aufbauen, die komplett lokal läuft. Die Quelldaten müssen die eigene Umgebung nie verlassen, was besonders für datensensible Branchen wie das Gesundheitswesen oder den Finanzsektor entscheidend ist. Solche Pipelines sind kompatibel mit verschiedenen KI-Modellen, von kommerziellen Anbietern wie OpenAI und Anthropic bis hin zu lokalen Modellen via Ollama.
Die Qualität synthetischer Daten hängt massgeblich vom Prompt-Engineering ab. Fünf Spezifikationen sind dabei unverzichtbar: das gewünschte Volumen, das exakte Schema mit Spaltentypen, Constraints wie Wertebereiche oder Abhängigkeiten zwischen Feldern, der Grad an Realismus in den Verteilungen sowie das Ausgabeformat. Ein schlecht formulierter Prompt führt unweigerlich zu unbrauchbaren Daten, ganz nach dem Prinzip "Garbage in, garbage out".
Lektion 3: Einsatzgebiete in der Praxis
Im Finanzsektor gehören synthetische Daten längst zum Standardrepertoire. Banken und Versicherungen nutzen sie, um Betrugserkennungssysteme mit tausenden simulierten Szenarien zu trainieren, ohne gegen die DSGVO zu verstossen. Ein konkretes Beispiel: Eine Versicherung möchte ihr Modell zur Erkennung betrügorischer Schadenmeldungen verbessern. Echte Betrugsfälle machen weniger als ein Prozent aller Meldungen aus, was das Training erschwert. Mit synthetischen Daten lassen sich beliebig viele realistische Betrugsszenarien generieren, die die statistische Verteilung echter Fälle widerspiegeln, aber keine realen Kunden referenzieren.
In der Medizin eröffnen synthetische Daten völlig neue Möglichkeiten. Patientendaten unterliegen besonders strengen Datenschutzanforderungen, gleichzeitig sind grosse Datensätze für die Entwicklung diagnostischer KI-Systeme unverzichtbar. Krankenhäuser können synthetische Patientenakten generieren, die realistische Krankheitsverläufe und Behandlungsmuster abbilden, ohne dass echte Patientendaten das Kliniknetzwerk verlassen. Der Unstructured Data Catalog von Tonic.ai macht seit Januar 2026 sogar textlastige Umgebungen wie Patientenakten oder juristische Verträge sicher für KI-Workflows nutzbar.
Die Automobilindustrie setzt synthetische Daten massiv für das Training autonomer Fahrsysteme ein. Statt Millionen Testkilometer auf der Strasse zu absolvieren, werden kritische Verkehrssituationen, Wetterszenarien und Randlälle in Simulationsumgebungen erzeugt. Ein Fussgänger, der bei Nebel plötzlich hinter einem parkenden Fahrzeug hervortritt, lässt sich in der Simulation tausendfach variieren, ohne dass jemals ein Mensch in Gefahr gerät.
Auch im E-Commerce und SaaS-Bereich gewinnen synthetische Daten an Bedeutung. Unternehmen generieren realistische Kundenverhaltendaten, um Empfehlungssysteme zu testen, ohne auf echte Nutzerdaten zurückzugreifen. Die empfohlene Grösse solcher Datensätze liegt bei 5.000 bis 10.000 Zeilen, wobei besonderer Wert auf logische Konsistenz gelegt werden muss, etwa dass Diagnose-Behandlung-Paare oder Produkt-Kaufmuster in sich stimmig sind.
Lektion 4: Tools und Plattformen im Vergleich
Der Markt für synthetische Daten hat sich 2025 und 2026 stark ausdifferenziert. Gretel.ai, das im März 2025 für über 320 Millionen US-Dollar von Nvidia übernommen wurde, richtet sich stark an Entwickler und KI-Ingenieure. Die Plattform bietet leistungsstarke APIs zur Anonymisierung und Generierung sicherer Daten, unterstützt Fine-Tuning-Möglichkeiten und behält komplexe relationale Datenstrukturen bei. Detaillierte Qualitätsmetriken erlauben die Überprüfung von Genauigkeit und Datenschutz.
Mostly AI gilt als Pionier im Bereich tabellarischer Daten und geniesst hohes Vertrauen bei Fortune-500-Unternehmen und Regierungsbehörden. Im Januar 2025 veröffentlichte das Unternehmen ein branchenführendes Open-Source-SDK, um die Demokratisierung synthetischer Daten voranzutreiben. Für Unternehmen, die erste Erfahrungen sammeln möchten, bietet Mostly AI damit einen niedrigschwelligen Einstieg.
Tonic.ai hat sich strategisch auf unstrukturierte Daten positioniert und damit eine wichtige Marktlücke geschlossen. Hazy hingegen bietet eine hochsichere Plattform, bei der sensible Informationen ihre ursprüngliche Quellumgebung nie verlassen müssen. Für den asiatischen Markt hat AxxonAI aus Malaysia im Februar 2026 das erste auf synthetische Daten spezialisierte LLM vorgestellt, das LLMs, GANs, RAG und agentische Workflows kombiniert und damit ganze operative Umgebungen simulieren kann.
Bei der Tool-Auswahl sollten Unternehmen vier Kriterien berücksichtigen: Erstens die Datentypen, denn manche Tools sind auf tabellarische Daten spezialisiert, während andere auch Texte, Bilder oder Zeitreihen abdecken. Zweitens die Deployment-Option, also ob die Lösung in der Cloud, On-Premise oder hybrid betrieben werden kann. Drittens die regulatorische Compliance, insbesondere Zertifizierungen und Audit-Fähigkeiten. Viertens die Integration in bestehende Datenpipelines und ML-Workflows.
Lektion 5: DSGVO, Privacy und rechtliche Rahmenbedingungen
Die Europäische Union hat mit der Data Union Strategy Ende 2025 und Anfang 2026 den Aufbau von Kapazitäten für synthetische Daten massiv vorangetrieben. Sogenannte Datenlabore verbinden europäische Datenräume sicher mit dem KI-Ökosystem. Der zentrale regulatorische Vorteil synthetischer Daten: Wenn sie korrekt generiert werden, gelten sie nicht als personenbezogene Daten im Sinne der DSGVO und können daher frei für Training, Analyse und Weitergabe genutzt werden.
Allerdings ist diese Befreiung an strenge Voraussetzungen geknüpft. Die generierten Daten dürfen keinerlei Rückschlüsse auf echte Personen erlauben, was durch sogenannte Privacy-Enhancing Technologies sichergestellt wird. Dazu gehören Differential Privacy, bei der den Daten kontrolliertes Rauschen hinzugefügt wird, um die Identifizierbarkeit Einzelner zu verhindern, sowie K-Anonymity und L-Diversity, die sicherstellen, dass jede Person in einer Gruppe von mindestens K anderen nicht unterscheidbar ist. Federated Learning ermöglicht es darüber hinaus, Modelle über verteilte Datensätze zu trainieren, ohne die Rohdaten zu zentralisieren.
In der Praxis bedeutet das für Unternehmen: Bevor synthetische Daten als datenschutzkonform behandelt werden dürfen, muss ein sogenannter Re-Identifikationstest durchgeführt werden. Dieser prüft mit verschiedenen statistischen Methoden, ob sich aus den synthetischen Daten Rückschlüsse auf echte Personen im Quelldatensatz ziehen lassen. Nur wenn dieses Risiko unter einem definierten Schwellenwert liegt, ist die DSGVO-Konformität gegeben.
Für Unternehmen in hochregulierten Branchen ergibt sich daraus eine klare Handlungsempfehlung: Die Einführung synthetischer Daten sollte von Anfang an in Abstimmung mit dem Datenschutzbeauftragten und der Rechtsabteilung erfolgen. Ein dokumentierter Prozess von der Datengenerierung über die Qualitätssicherung bis zum Re-Identifikationstest schafft die nötige Rechtssicherheit und kann sogar als Wettbewerbsvorteil in der Kundenkommunikation dienen.
Lektion 6: Qualität sichern und Bias vermeiden
Synthetische Daten sind kein Allheilmittel. Wenn der Quelldatensatz bereits systematische Verzerrungen enthält, werden diese in den synthetischen Daten reproduziert oder sogar verstärkt. Dieses Phänomen, bekannt als Bias-Amplifikation, ist eines der grössten Risiken beim Einsatz synthetischer Daten. Ein Kreditscoring-Modell, das mit verzerrten historischen Daten trainiert wurde, wird auch mit synthetischen Varianten dieser Daten diskriminierende Entscheidungen treffen.
Die Qualitätssicherung synthetischer Daten umfasst mehrere Dimensionen. Die statistische Treue misst, wie genau die synthetischen Daten die Verteilungen des Originals abbilden. Dazu werden Kennzahlen wie Kolmogorov-Smirnov-Tests oder Jensen-Shannon-Divergenz herangezogen. Die Nützlichkeit prüft, ob ein auf synthetischen Daten trainiertes Modell vergleichbare Ergebnisse liefert wie eines, das mit echten Daten trainiert wurde. Die Privatsphäre wird über den bereits beschriebenen Re-Identifikationstest sichergestellt.
Ein weiteres Risiko ist der sogenannte Modell-Kollaps. Wenn synthetische Daten, die von einem KI-Modell erzeugt wurden, wiederum zum Training desselben oder eines ähnlichen Modells verwendet werden, kann es zu einer progressiven Verarmung der Datenvielfalt kommen. Die Verteilungen werden mit jeder Generation enger, seltene aber wichtige Muster verschwinden, und das Modell verliert seine Fähigkeit, mit ungewöhnlichen Eingaben umzugehen. Die Lösung liegt in hybriden Ansätzen, bei denen synthetische Daten stets mit einem Anteil echter Daten kombiniert werden.
Für die praktische Umsetzung empfiehlt sich ein dreistufiger Validierungsprozess: Zunächst eine automatisierte statistische Prüfung der Verteilungen, dann ein ML-basierter Nützlichkeitstest mit Vergleichsmodellen, und schliesslich eine manülle Stichprobenprüfung durch Domänenexperten, die die inhaltliche Plausibilität bewerten. Dieser Prozess sollte dokumentiert und in die reguläre Daten-Governance des Unternehmens integriert werden.
Lektion 7: Die KI-Datenstrategie für Ihr Unternehmen
Eine moderne KI-Datenstrategie beginnt nicht mit der Auswahl eines Tools, sondern mit der Bestandsaufnahme: Welche Daten hat das Unternehmen, welche braucht es, und wo liegen die Lücken? Synthetische Daten sind dabei kein Ersatz für eine solide Dateninfrastruktur, sondern eine Ergänzung, die bestimmte Probleme gezielt löst. Typische Einsatzszenarien sind das Auffüllen unterrepräsentierter Klassen in Trainingsdaten, die Erstellung von Testdaten für Entwicklungsumgebungen, die Anonymisierung sensibler Datensätze für externe Weitergabe und das Simulieren zukünftiger Szenarien.
Die strategische Dimension geht über reine Technik hinaus. Synthetische Daten werden zunehmend als Frage der Datensouveränität verstanden. Unternehmen, die ihre eigenen synthetischen Datensätze erzeugen können, reduzieren ihre Abhängigkeit von externen Datenlieferanten und Cloud-Anbietern. In der geopolitischen Debatte um KI-Dominanz spielen synthetische Daten eine wachsende Rolle, weil sie es Ländern und Unternehmen ermöglichen, eigene Trainingsressourcen aufzubauen, ohne auf US-amerikanische oder chinesische Plattformen angewiesen zu sein.
Hybride Architekturen mit einer Kombination aus synthetischen und echten Daten, ergänzt durch lokal betriebene Small Language Models, setzen sich 2026 als Standard durch. Der Vorteil: Das Unternehmen behält die volle Kontrolle über seine Daten, kann regulatorische Anforderungen leichter erfüllen und bleibt technologisch flexibel. Die Implementierung solcher Architekturen erfordert allerdings neue Kompetenzen im Bereich LLMOps, also dem systematischen Betrieb und der Wartung grosser Sprachmodelle in Produktionsumgebungen.
Der wichtigste Rat für den Einstieg: Beginnen Sie mit einem klar abgegrenzten Anwendungsfall, bei dem der Nutzen synthetischer Daten offensichtlich ist, etwa Testdaten für die Softwareentwicklung oder Trainingsdaten für ein Klassifikationsmodell. Sammeln Sie Erfahrungen mit einem der beschriebenen Tools, dokumentieren Sie Ihre Prozesse, und skalieren Sie dann schrittweise. Synthetische Daten sind kein einmaliges Projekt, sondern eine Fähigkeit, die in der Daten-Governance des Unternehmens verankert werden muss.