Self-Hosting: Deine eigene KI-Infrastruktur
Einleitung
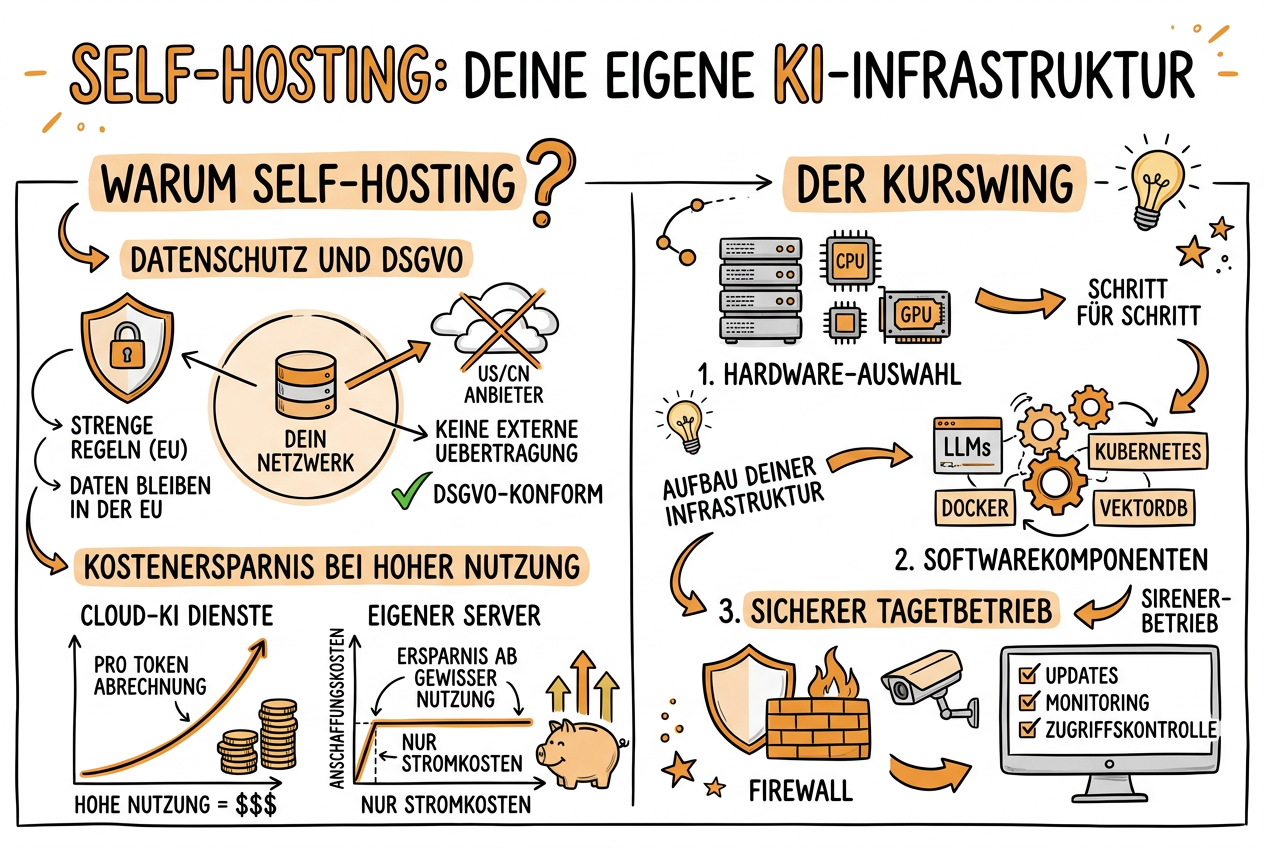
Die Abhängigkeit von amerikanischen und chinesischen Cloud-Anbietern ist für europäische Unternehmen zunehmend ein strategisches Risiko. Was passiert, wenn der Anbieter die Preise verdoppelt, den Dienst einstellt oder neue Nutzungsbedingungen diktiert? Self-Hosting löst dieses Problem grundsätzlich: Deine KI läuft auf deiner eigenen Hardware, unter deiner Kontrolle, DSGVO-konform.
In diesem Kurs lernst du, wie du eine komplette KI-Infrastruktur selbst aufbaust -- von der Hardware-Auswahl über die Softwarekomponenten bis zum sicheren Tagesbetrieb.
Warum Self-Hosting?
Datenschutz und DSGVO
In der EU gelten strenge Regeln für den Umgang mit personenbezogenen Daten. Wenn du Kundendaten, Mitarbeiterinformationen oder vertrauliche Geschäftsdokumente mit einer Cloud-KI verarbeitest, müssen diese Daten die EU nicht verlassen. Bei amerikanischen Anbietern ist das nicht garantiert.
Mit Self-Hosting bleibt alles in deinem Netzwerk. Keine Daten werden an externe Server gesendet. Die DSGVO-Konformität ist damit grundsätzlich gegeben.
Kostenersparnis bei hoher Nutzung
Cloud-KI-Dienste rechnen pro Token ab. Bei geringer Nutzung ist das günstig. Bei hoher Nutzung -- z.B. wenn ein ganzes Team täglich mit KI arbeitet oder Agenten rund um die Uhr laufen -- summieren sich die Kosten schnell auf tausende Euro pro Monat.
Ein eigener Server hat Anschaffungskosten, danach fallen nur noch Stromkosten an. Ab einem gewissen Nutzungsvolumen ist Self-Hosting deutlich günstiger.
Unabhängigkeit
Vier der fünf meistgenutzten KI-Modelle nach Tokenverbrauch sind mittlerweile Open-Weight-Modelle, die zusammen rund 45% des Marktes ausmachen -- bei einem Bruchteil der Kosten. Du bist nicht an einen Anbieter gebunden und kannst jederzeit das Modell wechseln.
Die Softwarekomponenten
Ollama: Modelle lokal ausführen
Ollama ist das Standardwerkzeug zum Ausführen von lokalen KI-Modellen. Ein einziger Befehl genügt, um ein Modell herunterzuladen und zu starten:
- Installation über die Ollama-Website oder per Paketmanager
- Modelle werden mit einem Befehl heruntergeladen
- API läuft standardmässig auf dem lokalen Rechner
- Unterstützt alle gängigen Open-Source-Modelle
Welche Modelle für welchen Zweck?
Für allgemeine Aufgaben (Text, Analyse, Zusammenfassung):
- Llama 3.3 (Meta) -- vielseitig und bewährt
- Qwen 2.5 (Alibaba) -- besonders stark in mehrsprachigen Aufgaben
- Mistral Large (Frankreich) -- europäisches Modell, effizient
Für Programmierung:
- Qwen Coder -- spezialisiert auf Code-Aufgaben
- DeepSeek Coder -- beeindruckende Leistung trotz kompakter Grösse
Für Embedding (RAG):
- All-MiniLM-L6-V2 -- Standard, funktioniert zuverlässig
- nomic-embed-text -- gute Alternative für längere Texte
Kompakte Modelle für schwäche Hardware:
- Llama 3.2 3B -- läuft auch auf älterer Hardware
- Phi-3 Mini -- Microsofts kompaktes Modell
OpenWebUI: Die Benutzeroberfläche
Wie im vorherigen Kurs beschrieben, ist OpenWebUI die Standard-Oberfläche für lokale KI. Für das Self-Hosting einer Teamlösung bietet es zusätzlich:
- Multi-User-Verwaltung -- Benutzerkonten mit unterschiedlichen Rollen und Rechten
- Admin-Dashboard -- Übersicht über Nutzung, Modelle und Einstellungen
- Modell-Zuweisung -- kontrolliere, wer welche Modelle nutzen darf
- Wissens-Verwaltung -- RAG-Kollektionen für verschiedene Teams oder Abteilungen
Vektordatenbank für RAG
OpenWebUI bringt eine integrierte Vektordatenbank mit. Für grössere Installationen kannst du eine dedizierte Lösung wie ChromaDB oder Qdrant einsetzen:
- Integrierte Lösung: Reicht für Teams bis ca. 50 Personen und moderate Dokumentmengen
- Dedizierte Datenbank: Empfohlen ab grösseren Dokumentsammlungen oder wenn mehrere Anwendungen auf die gleiche Wissensbasis zugreifen sollen
Hardware-Optionen
Option 1: Desktop-PC oder Workstation
Für Einzelpersonen oder kleine Teams (2-5 Personen)
- GPU: NVIDIA RTX 4070 oder besser (mindestens 12 GB VRAM)
- RAM: 32 GB oder mehr
- Storage: SSD mit mindestens 500 GB (Modelle brauchen Platz)
- Kosten: 1.500-3.000 Euro
Damit laufen Modelle mit bis zu 13 Milliarden Parametern flüssig. Für grössere Modelle brauchst du mehr VRAM.
Option 2: Dedizierter Server
Für Teams (5-20 Personen)
- GPU: NVIDIA RTX 4090 oder A-Serie (24+ GB VRAM)
- RAM: 64 GB oder mehr
- Storage: NVMe SSD, 1 TB+
- Kosten: 3.000-8.000 Euro
Damit kannst du auch grössere Modelle mit 30-70 Milliarden Parametern betreiben, die qualitativ deutlich näher an Cloud-Modelle herankommen.
Option 3: Cloud-Server (Self-Managed)
Für Flexibilität ohne eigene Hardware
- Anbieter: Hetzner (EU), OVH (EU), AWS, Google Cloud
- GPU-Server: Ab ca. 100-500 Euro/Monat je nach GPU
- Vorteil: Skalierbar, keine Hardware-Wartung
- Nachteil: Laufende Kosten, Daten liegen bei einem Hosting-Anbieter (aber in der EU)
Empfehlung für EU-Compliance: Hetzner oder OVH als europäische Anbieter mit Rechenzentren in Deutschland bzw. Frankreich.
Option 4: Mac Mini / Mac Studio
Für Apple-Ökosysteme
- Mac Mini M4 Pro: 24 GB Unified Memory, ca. 1.800 Euro
- Mac Studio M4 Ultra: 128 GB Unified Memory, ab ca. 4.500 Euro
- Vorteil: Leise, stromsparend, Apple Silicon ist effizient für KI
- Nachteil: Weniger flexibel als NVIDIA-Lösungen
Apples Unified Memory Architektur erlaubt es, Modelle zu betreiben, die normalerweise mehr VRAM brauchen würden, da CPU und GPU sich den Speicher teilen.
Installation Schritt für Schritt
Grundinstallation
1. Betriebssystem:
- Linux (Ubuntu 22.04 LTS empfohlen) für Server
- macOS für Mac-basierte Setups
- Windows funktioniert, aber Linux ist für Server-Betrieb besser geeignet
2. Docker installieren: OpenWebUI und viele Zusatzkomponenten laufen am einfachsten in Docker-Containern. Das vereinfacht Installation, Updates und Wartung.
3. Ollama installieren: Ein Befehl genügt. Ollama erkennt automatisch vorhandene GPUs und nutzt sie.
4. OpenWebUI starten: Per Docker-Befehl oder Docker Compose starten. OpenWebUI verbindet sich automatisch mit Ollama.
5. Erstes Modell herunterladen: Über die OpenWebUI-Oberfläche oder per Terminal-Befehl.
Sicherheitseinrichtung
Zugriffsschutz:
- OpenWebUI nur im internen Netzwerk erreichbar machen
- Für externen Zugriff: VPN oder Reverse Proxy mit SSL/TLS
- Standard-Admin-Passwort sofort ändern
Netzwerk:
- Firewall konfigurieren -- nur notwendige Ports öffnen
- HTTPS für alle Verbindungen erzwingen
- Regelmässige Updates für alle Softwarekomponenten
Datensicherung:
- Regelmässige Backups der Konfiguration und der RAG-Datenbank
- Modelle müssen nicht gesichert werden -- sie können jederzeit neu heruntergeladen werden
Der europäische Kontext
Digitale Souveränität
Die Abhängigkeit von amerikanischen und chinesischen KI-Anbietern ist ein zunehmendes Thema in der EU-Politik. Wenn die gesamte KI-Infrastruktur aus dem Ausland kommt, schafft das strategische Risiken:
- Politische Risiken: Sanktionen, Exportbeschränkungen, Regulierungsänderungen
- Wirtschaftliche Risiken: Preiserhöhungen, Lizenzänderungen, Vendor Lock-in
- Compliance-Risiken: Datenschutzverletzungen, unklare Datenverarbeitung
Open Source aus China
China hat früh und strategisch auf Open Source gesetzt. Modelle wie Qwen von Alibaba und DeepSeek erreichen mittlerweile Top-Positionen in den Benchmarks. Das bedeutet: Einige der besten kostenlosen Modelle kommen aus China.
Für europäische Unternehmen ist das Fluch und Segen zugleich. Die Modelle sind leistungsstark und kostenlos, aber die Herkunft wirft Fragen auf. Da bei Self-Hosting die Modelle lokal laufen und keine Daten an den Hersteller senden, ist das Risiko in der Praxis gering -- die Gewichte sind öffentlich auditierbar.
Europäische Alternativen
- Mistral (Frankreich): Das stärkste europäische KI-Unternehmen
- Aleph Alpha (Deutschland): Auf Enterprise-Lösungen spezialisiert
- AI21 Labs (EU-Fokus): Zunehmend mit europäischen Partnerschaften
n8n Self-Hosted: Automatisierung unter eigener Kontrolle
Warum n8n selbst hosten?
n8n ist nicht nur ein Cloud-Dienst -- es kann auch komplett auf eigenem Server betrieben werden. In Kombination mit lokaler KI ergibt sich eine vollständige Automatisierungsplattform ohne externe Abhängigkeiten.
Die Vorteile gegenüber der Cloud-Version
- Keine Credit-Limits -- unbegrenzte Workflow-Ausführungen
- Volle Datenkontrolle -- alle Daten bleiben auf deinem Server
- API-Integration -- direkte Anbindung an deine lokalen KI-Modelle
- Kostenersparnis -- keine monatlichen Gebühren für n8n selbst
Typisches Self-Hosted Setup
Ein typischer KI-Server für ein mittelständisches Unternehmen könnte so aussehen:
- Ollama für lokale KI-Modelle
- OpenWebUI als Chat-Oberfläche für Mitarbeiter
- n8n für automatisierte Workflows
- ChromaDB als zentrale Vektordatenbank
- Alles hinter einem Reverse Proxy mit SSL-Zertifikat
Betrieb und Wartung
Monitoring
- Überwache GPU-Auslastung und Temperatur
- Prüfe regelmässig die Verfügbarkeit der Dienste
- Behalte den Speicherplatz im Auge -- neue Modelle brauchen Platz
Updates
- OpenWebUI und Ollama erhalten regelmässig Updates mit neuen Features
- Neue Modellversionen erscheinen häufig -- prüfe monatlich, ob es bessere Alternativen gibt
- Sicherheitsupdates für das Betriebssystem zeitnah einspielen
Skalierung
- Mehr Nutzer: Leistungsfähigere GPU oder mehrere GPUs
- Mehr Wissen: Dedizierte Vektordatenbank statt integrierter Lösung
- Mehr Modelle: Grössere SSD, eventüll NAS-Anbindung
Fazit
Self-Hosting einer KI-Infrastruktur ist keine Raketenwissenschaft mehr -- die Tools sind reif genug für den produktiven Einsatz:
- DSGVO-Konformität ist mit Self-Hosting grundsätzlich gelöst
- Die Kosten amortisieren sich bei regelmässiger Nutzung schnell
- Open-Source-Modelle sind konkurrenzfähig mit kommerziellen Angeboten
- Ollama + OpenWebUI + n8n bilden eine vollständige, unabhängige KI-Plattform
- Europäische Hosting-Anbieter wie Hetzner bieten günstige GPU-Server in der EU
- Digitale Souveränität ist nicht nur ein politisches Schlagwort, sondern ein konkreter Wettbewerbsvorteil
Der beste Zeitpunkt zum Starten ist jetzt. Die Hardware wird günstiger, die Modelle werden besser, und die Tools werden einfacher. Wer heute anfängt, hat morgen einen Vorsprung.