Multimodale KI: Text, Bild, Audio und Video intelligent verbinden
Lektion 1: Was multimodale KI wirklich bedeutet
Wenn wir die Welt wahrnehmen, nutzen wir nie nur einen einzigen Sinn. Wir sehen ein Gesicht, hören eine Stimme, lesen Körpersprache und verstehen den Kontext -- alles gleichzeitig. Genau diese Fähigkeit, mehrere Informationsquellen zu einem Gesamtbild zu verschmelzen, macht multimodale KI aus. Statt nur Text zu verarbeiten wie frühe Sprachmodelle, können multimodale Systeme Text, Bilder, Audio, Video und sogar Sensordaten gleichzeitig verstehen und miteinander in Beziehung setzen.
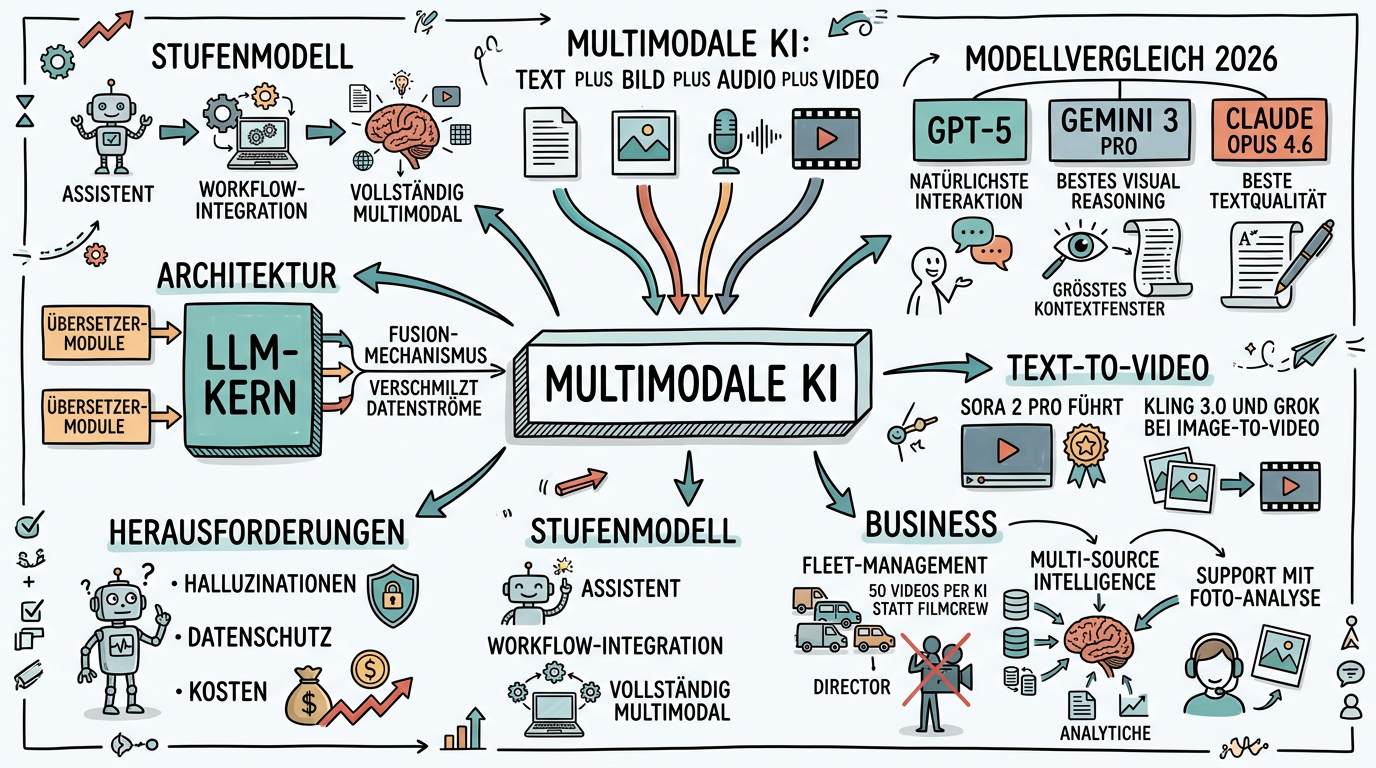
Die technische Architektur dahinter ist elegant und überraschend nachvollziehbar. Im Zentrum steht ein grosses Sprachmodell (LLM) als Kern -- quasi das "Gehirn" des Systems. Um diesen Kern herum gibt es spezialisierte Übersetzer-Module: neuronale Netzwerke, die darauf trainiert sind, Bilder, Audioaufnahmen oder Videodaten in die gemeinsame Sprache des LLM zu übersetzen -- in sogenannte Vektoren im Embedding-Raum. Ein Bild eines Hundes und das Wort "Hund" landen so in der gleichen "Nachbarschaft" im mathematischen Raum des Modells. Der entscheidende Mechanismus ist die Fusion: das Verschmelzen verschiedener Datenströme zu einem einheitlichen Verständnis, das reicher ist als jede einzelne Modalität für sich.
In der Praxis bedeutet das: Du kannst einem multimodalen KI-Modell ein Foto von einem Maschinendefekt zeigen und gleichzeitig die Fehlermeldung als Text mitgeben -- und das System versteht den Zusammenhang zwischen dem sichtbaren Schaden und der technischen Beschreibung. Oder du lädst ein Besprechungsvideo hoch, und die KI fasst nicht nur das Gesprochene zusammen, sondern bemerkt auch, welche Präsentationsfolien gezeigt wurden und wer wann gesprochen hat. Diese Art der modalitätsübergreifenden Intelligenz war noch vor zwei Jahren Science Fiction und ist heute in Tools wie GPT-4o, Gemini und Claude verfügbar.
Lektion 2: Die grossen Modelle im Vergleich -- GPT, Gemini und Claude
Der Markt für multimodale KI-Modelle hat sich Anfang 2026 zu einem Dreikampf zwischen OpenAI, Google und Anthropic entwickelt, wobei jedes Modell unterschiedliche Stärken mitbringt. Für Anwender ist es entscheidend zu verstehen, welches Modell für welche Aufgabe am besten geeignet ist, denn die Unterschiede sind erheblich und praxisrelevant.
OpenAIs GPT-5 und das darauf basierende ChatGPT bieten die natürlichste multimodale Echtzeitinteraktion. Du kannst mit dem System sprechen, ihm gleichzeitig deine Kamera zeigen und es reagiert in Echtzeit auf das, was es sieht und hört. Diese nahtlose Verbindung von Text, Bild und Sprache macht ChatGPT zum stärksten Werkzeug für Alltagsaufgaben und spontane Interaktionen. Wenn du unterwegs schnell ein Foto analysieren, ein Etikett übersetzen oder eine Situation erklärt haben möchtest, ist GPT-5 die erste Wahl. Die Stärke liegt in der Geschwindigkeit und der Natürlichkeit der Interaktion, während die analytische Tiefe bei komplexen Aufgaben manchmal hinter den Wettbewerbern zurückbleibt.
Googles Gemini 3 Pro hat sich als Spitzenreiter im visüllen Reasoning etabliert und erreicht auf spezialisierten Benchmarks Werte von über 79 Prozent. Besonders beeindruckend ist das riesige Kontextfenster, das die Analyse von bis zu zwei Stunden Videomaterial am Stück ermöglicht. Damit eignet sich Gemini hervorragend für die Analyse grosser Dokumentensammlungen, langer Videos oder umfangreicher Bilddatensätze. Ein Anwalt kann beispielsweise hunderte Seiten Vertragswerk hochladen und Gemini nach spezifischen Klauseln suchen lassen, während ein Marktforscher Stunden von Fokusgruppen-Videos zusammenfassen lassen kann.
Anthropics Claude Opus 4.6 verfolgt eine andere Philosophie. Statt auf maximale multimodale Breite zu setzen, liegt der Fokus auf Textqualität, Code und präziser Analyse. Claude kann Bilder und Dokumente verstehen und analysieren, ist aber besonders stark, wenn es darum geht, aus visüllen Informationen präzise und gut strukturierte Texte zu generieren. Die text-first Designphilosophie macht Claude zum bevorzugten Werkzeug für Aufgaben, bei denen aus multimodalen Eingaben hochwertige schriftliche Ergebnisse entstehen sollen -- etwa technische Dokumentationen auf Basis von Screenshots oder detaillierte Berichte aus Diagrammen und Tabellen.
Lektion 3: Bilder und Dokumente verstehen -- Vision-KI in der Praxis
Die Fähigkeit von KI-Modellen, Bilder und Dokumente zu verstehen, hat sich in den vergangenen zwei Jahren dramatisch verbessert und eröffnet völlig neue Anwendungsmöglichkeiten im Berufsalltag. Dabei geht es längst nicht mehr nur um die Erkennung von Objekten in Fotos, sondern um ein tiefes kontextülles Verständnis visüller Informationen -- einschliesslich handschriftlicher Notizen, komplexer Diagramme und mehrsprachiger Dokumente.
Im Unternehmensalltag zeigt sich der Nutzen besonders deutlich bei der Dokumentenverarbeitung. Stell dir vor, du erhältst eine eingescannte Rechnung auf Italienisch, ein handgeschriebenes Meeting-Protokoll und eine technische Zeichnung mit Massangaben. Ein multimodales KI-Modell kann alle drei Dokumente analysieren, die relevanten Informationen extrahieren und in ein einheitliches Format übersetzen -- in Sekunden statt in Stunden. Besonders beeindruckend ist die Fähigkeit, auch unscharfe oder teilweise verdeckte Texte zu erkennen, Tabellen korrekt zu interpretieren und sogar die räumliche Anordnung von Elementen auf einer Seite zu verstehen.
Ein konkretes Anwendungsbeispiel aus der Praxis: Ein deutsches Maschinenbauunternehmen nutzt Vision-KI, um eingehende technische Anfragen zu verarbeiten. Kunden schicken oft Fotos von Maschinenteilen, handschriftliche Skizzen oder Screenshots aus CAD-Programmen. Früher musste ein Ingenieur jede Anfrage manüll sichten und die relevanten Informationen herausarbeiten. Heute analysiert die KI das eingehende Material, identifiziert das betroffene Bauteil, gleicht es mit dem Produktkatalog ab und erstellt einen ersten Antwortnentwurf. Der Ingenieur prüft und verfeinert den Entwurf, statt bei null anzufangen. Die Bearbeitungszeit pro Anfrage sank von durchschnittlich zwei Stunden auf 30 Minuten.
Auch im Qualitätsmanagement spielt Vision-KI eine wachsende Rolle. Kameras an Produktionslinien können in Kombination mit multimodalen Modellen nicht nur offensichtliche Defekte erkennen, sondern auch subtile Abweichungen in Farbe, Textur oder Form identifizieren, die einem menschlichen Prüfer nach Stunden monotoner Arbeit entgehen würden. Die KI wird dabei nicht als Ersatz für menschliche Qualitätskontrolle eingesetzt, sondern als zusätzliche Sicherheitsebene, die Auffälligkeiten markiert und zur menschlichen Überprüfung weiterleitet.
Lektion 4: Audio und Video -- Die nächste Dimension
Während die Bildanalyse bereits breit im Einsatz ist, stehen Audio- und Videoverarbeitung durch KI erst am Beginn ihrer praktischen Nutzung in Unternehmen. Die Fortschritte in diesem Bereich sind jedoch rasant, und die Anwendungsmöglichkeiten gehen weit über einfache Transkription hinaus. Multimodale KI kann Audio und Video nicht nur in Text umwandeln, sondern den Inhalt verstehen, analysieren und in Beziehung zu anderen Informationen setzen.
Im Bereich Audio hat sich die KI-gestützte Transkription und Analyse bereits als Standardwerkzeug etabliert. Tools wie Otter.ai oder die eingebauten Funktionen von Microsoft Teams und Google Meet erzeugen automatische Mitschriften von Besprechungen. Doch multimodale KI geht einen entscheidenden Schritt weiter: Sie kann Sprecherwechsel erkennen, die emotionale Tonalität einschätzen, Kernaussagen von Nebensächlichkeiten unterscheiden und strukturierte Zusammenfassungen mit Aktionspunkten erstellen. Ein einstündiges Teammeeting wird in wenigen Sekunden zu einem präzisen Protokoll mit klaren Zuständigkeiten und Deadlines -- und das nicht durch einfaches Abtippen, sondern durch echtes inhaltliches Verständnis.
Die Videoanalyse eröffnet noch weitreichendere Möglichkeiten. Googles Gemini kann bis zu zwei Stunden Videomaterial am Stück analysieren und dabei sowohl den gesprochenen Inhalt als auch die visüllen Elemente berücksichtigen. Ein beeindruckendes Praxisbeispiel kommt aus der britischen Logistikbranche: Ein Flottenmanagement-Unternehmen, das rund 20 Prozent aller britischen Lieferflotten betreut, nutzt multimodale KI zur Erstellung von Sicherheitsschulungsvideos. Früher waren dafür komplette Filmteams nötig, die Strassen sperren und tagelange Dreharbeiten durchführen mussten. Heute erstellt das Unternehmen über 50 produktionsreife Schulungsvideos per KI -- und diese Videos retten nachweislich Leben, weil sie schneller und in grösserer Zahl produziert werden können als mit traditionellen Methoden.
Auch die Sentiment-Analyse von Kundengesprächen profitiert von multimodaler KI. Statt nur den Text eines Telefongesprächs zu analysieren, kann die KI auch den Tonfall, das Sprechtempo und die Pausen berücksichtigen. Ein Kundenservice-Team erkennt so frühzeitig, wenn ein Gespräch eskaliert, auch wenn die Worte noch höflich sind. Diese Kombination aus Text- und Audioanalyse liefert ein deutlich genaueres Bild der Kundenzufriedenheit als jede einzelne Modalität für sich.
Lektion 5: Text-to-Image und Text-to-Video -- Inhalte generieren
Neben dem Verstehen von Bildern und Videos kann multimodale KI auch neue visülle Inhalte erzeugen. Die Entwicklung von Text-to-Image- und Text-to-Video-Tools hat 2025 und 2026 einen enormen Qualitätssprung gemacht, und die Ergebnisse sind inzwischen so überzeugend, dass sie in vielen Bereichen professionelle Produktion ersetzen oder ergänzen können. Gleichzeitig wirft diese Fähigkeit wichtige ethische Fragen auf, die jeder Nutzer verstehen sollte.
Im Bereich Text-to-Image haben sich DALL-E 3, Midjourney und das Open-Source-Modell Flux als führende Werkzeuge etabliert. Die Qualität der generierten Bilder hat ein Niveau erreicht, auf dem sie von professionellen Fotos oder Illustrationen kaum noch zu unterscheiden sind. Für Unternehmen bedeutet das: Produktvisualisierungen, Marketing-Grafiken, Präsentationsbilder und Social-Media-Content können in Minuten statt in Tagen erstellt werden. Ein mittelständisches Unternehmen, das früher für jedes Produktfoto einen Fotografen beauftragen musste, kann nun Varianten in verschiedenen Umgebungen, Beleuchtungen und Perspektiven generieren lassen -- zu einem Bruchteil der Kosten.
Text-to-Video ist der jüngste und vielleicht beeindruckendste Bereich. OpenAIs Sora 2 Pro dominiert bei der reinen Textgenerierung mit beeindruckender Kinematographie, integrierter Musik und Voiceover. Kling 3.0 und Grok Imagine liegen gleichauf an der Spitze bei der Animation bestehender Bilder (Image-to-Video). Alle Tools haben allerdings noch erkennbare Schwächen: Physik wird manchmal falsch dargestellt, Hände haben gelegentlich zu viele Finger, und logische Zusammenhänge in komplexen Szenen können inkonsistent sein. Für professionelle Videoproduktion bedeutet das: Die Tools eignen sich hervorragend für Konzeptvideos, Storyboards, Social-Media-Clips und Erklärvideos, ersetzen aber noch nicht die komplette Filmproduktion für anspruchsvolle Projekte.
Die ethische Dimension darf bei all der Begeisterung nicht vergessen werden. Generierte Bilder und Videos können für Desinformation und Deepfakes missbraucht werden. Es gibt bereits Fälle, in denen KI-generierte Videos für Betrug und Manipulation eingesetzt wurden. Als verantwortungsvoller Nutzer solltest du generierte Inhalte immer als solche kennzeichnen -- nicht nur aus ethischen Gründen, sondern auch weil der EU AI Act Transparenzpflichten für KI-generierte Inhalte vorsieht.
Lektion 6: Multimodale KI im Unternehmenseinsatz -- Strategien und Praxisbeispiele
Die strategische Nutzung multimodaler KI im Unternehmen unterscheidet sich fundamental von der privaten Nutzung eines Chatbots. Es geht nicht darum, gelegentlich ein Bild analysieren zu lassen, sondern darum, multimodale Fähigkeiten systematisch in Geschäftsprozesse zu integrieren. Der Ansatz, den IBM-Experte Mark Polyak als "Multi-Source Intelligence" bezeichnet, beschreibt den Kern dieser Strategie: Verschiedene Datenquellen zusammenführen, um ein holistisches Bild zu gewinnen, das bessere Entscheidungen ermöglicht.
Ein überzeugender Anwendungsfall findet sich im Marketing und in der Marktforschung. Statt nur Verkaufszahlen zu analysieren, kann multimodale KI gleichzeitig Social-Media-Posts (Text und Bilder), Kundenbewertungen (Text und Sentiment), Produktfotos der Konkurrenz (Bilder) und Werbevideos (Video und Audio) auswerten. Das Ergebnis ist ein vielschichtiges Verständnis der Marktposition, das weit über das hinausgeht, was eine reine Zahlenanalyse liefern könnte. Ein Modehersteller könnte beispielsweise erkennen, dass seine Produkte zwar gut bewertet werden, aber in Social-Media-Posts deutlich seltener fotografiert werden als die Konkurrenz -- ein Hinweis darauf, dass das Design zwar funktional, aber nicht "instagrammable" genug ist.
Im technischen Support und Kundenservice entfaltet multimodale KI besonderen Mehrwert. Kunden können ein Foto ihres Problems schicken, eine Sprachnachricht mit der Fehlerbeschreibung aufnehmen oder ein kurzes Video des Defekts aufzeichnen -- und die KI versteht alle drei Formate gleich gut. Das führt zu schnellerer Problemlösung, weniger Rückfragen und höherer Kundenzufriedenheit. Ein Elektronikhersteller berichtet, dass die durchschnittliche Lösungszeit im Support um 40 Prozent sank, nachdem multimodale KI eingeführt wurde, weil die KI aus dem eingesendeten Foto oft sofort erkennt, welches Bauteil betroffen ist.
Auch in der Aus- und Weiterbildung verändert multimodale KI die Spielregeln. Statt statische Schulungsunterlagen zu erstellen, können Unternehmen personalisierte Lernmaterialien generieren, die Text, Bilder, Audio-Erklärungen und kurze Videoclips kombinieren. Ein Wartungstechniker erhält eine Anleitung, die nicht nur Text und Fotos enthält, sondern auch ein kurzes animiertes Video des Reparaturvorgangs -- automatisch generiert aus den technischen Dokumentationen und CAD-Zeichnungen des Produkts.
Lektion 7: Herausforderungen und Grenzen multimodaler KI
So beeindruckend die Fähigkeiten multimodaler KI auch sind, es gibt klare Grenzen und Herausforderungen, die du kennen solltest, bevor du multimodale Lösungen in deinem Unternehmen implementierst. Ein realistisches Verständnis dieser Grenzen schützt vor Enttäuschungen und hilft, die richtigen Erwartungen zu setzen.
Die erste und fundamentalste Grenze betrifft die sogenannten Halluzinationen. Multimodale KI-Modelle können mit grosser Überzeugung Dinge behaupten, die in den visüllen oder audiellen Eingaben gar nicht enthalten sind. Ein Modell könnte in einem Foto Details beschreiben, die nicht sichtbar sind, oder in einem Videotranskript Aussagen zuschreiben, die so nie gefallen sind. Diese Halluzinationen sind bei multimodalen Aufgaben oft schwerer zu erkennen als bei reinen Textaufgaben, weil der Nutzer möglicherweise nicht alle Details eines Bildes oder Videos selbst geprüft hat. Die Regel lautet: Je kritischer die Entscheidung, desto sorgfältiger muss die menschliche Überprüfung sein.
Die zweite Herausforderung sind Datenschutz und Datensicherheit. Wenn du Bilder, Videos oder Audioaufnahmen an ein Cloud-KI-System schickst, verlassen potenziell sensible Daten dein Unternehmen. Ein Foto einer Produktionsanlage kann Geschäftsgeheimnisse enthalten, ein Mitarbeitervideo fällt unter den Schutz der DSGVO, und Kundengespräche dürfen nicht ohne Einwilligung verarbeitet werden. Für multimodale Anwendungen gelten dieselben Datenschutzprinzipien wie für textbasierte KI, aber das Risiko ist höher, weil Bilder und Videos mehr unbeabsichtigte Informationen enthalten können als strukturierter Text.
Die dritte Grenze liegt im Energieverbrauch und den Kosten. Multimodale Modelle sind deutlich rechenintensiver als reine Textmodelle. Die Analyse eines einminütigen Videos kann so viel Rechenleistung erfordern wie die Verarbeitung hunderter Seiten Text. Das schlägt sich in den Kosten nieder: API-Aufrufe mit Bild- oder Videoeingaben sind typischerweise drei- bis zehnmal teurer als reine Textanfragen. Für den gelegentlichen Einsatz ist das vernachlässigbar, aber bei der systematischen Verarbeitung grosser Bild- oder Videobestände müssen die Kosten sorgfältig kalkuliert werden.
Lektion 8: Dein Einstieg in multimodale KI -- Praktisch und sofort
Multimodale KI muss kein Grossprojekt sein. Du kannst heute damit anfangen, multimodale Fähigkeiten in deinen Arbeitsalltag zu integrieren, und innerhalb weniger Wochen konkrete Ergebnisse erzielen. Der Schlüssel liegt darin, mit einfachen, risikoarmen Anwendungsfällen zu beginnen und schrittweise zu anspruchsvolleren Szenarien überzugehen.
Der einfachste Einstieg ist die Nutzung der multimodalen Fähigkeiten in Tools, die du vermutlich bereits verwendest. Wenn du einen ChatGPT Plus, Claude Pro oder Gemini Advanced Account hast, kannst du sofort Bilder hochladen und analysieren lassen. Starte mit Alltagsaufgaben: Fotografiere eine handschriftliche Notiz und lass sie digitalisieren. Lade einen Screenshot einer Fehlermeldung hoch und frage nach Lösungsvorschlägen. Schicke ein Foto eines Produkts und lass eine Marketingbeschreibung generieren. Diese einfachen Übungen trainieren dein Gespür dafür, wann multimodale KI Mehrwert liefert und wo ihre Grenzen liegen.
Im nächsten Schritt identifizierst du den Prozess in deinem Unternehmen, bei dem am meisten visülle Information anfällt, die heute manüll verarbeitet wird. Das können eingehende Kundenfotos im Support sein, Belege in der Buchhaltung, Zustandsfotos in der Wartung oder Produktbilder im E-Commerce. Genau hier liegt dein erster ernsthafter Anwendungsfall. Teste ihn zunächst manüll mit einem allgemeinen KI-Tool, miss die Zeitersparnis und die Qualität, und entscheide dann, ob sich die Investition in eine spezialisierte Lösung lohnt.
Für die langfristige Strategie empfiehlt sich ein Stufenmodell. In der ersten Phase nutzt du multimodale KI als persönlichen Assistenten für Einzelaufgaben. In der zweiten Phase integrierst du multimodale Analyse in bestehende Workflows, zum Beispiel durch API-Anbindung eines Vision-Modells an dein Ticketsystem oder CRM. In der dritten Phase baust du vollständig multimodale Prozesse auf, bei denen verschiedene Datentypen automatisch zusammengeführt und analysiert werden. Jede Phase baut auf den Erfahrungen der vorherigen auf und reduziert das Risiko von Fehlinvestitionen. Multimodale KI ist keine Revolution, die über Nacht passiert -- es ist eine Evolution, die mit kleinen, praktischen Schritten beginnt.