MCP Server selbst bauen: Eigene KI-Integrationen entwickeln
Lektion 1: Warum eigene MCP Server?
Das Model Context Protocol hat sich als universeller Standard etabliert, über den KI-Modelle auf externe Systeme zugreifen. Tausende vorgefertigte MCP Server existieren bereits für gängige Dienste wie GitHub, Slack, Google Drive oder Datenbanken. Doch in der Unternehmenspraxis reichen diese Standardlösungen oft nicht aus. Jedes Unternehmen hat eigene Systeme, proprietäre Datenbanken und spezifische Workflows, die sich nicht mit generischen Servern abbilden lassen. Genau hier wird die Fähigkeit, eigene MCP Server zu entwickeln, zur strategischen Kompetenz.
Ein Beispiel verdeutlicht den Bedarf: Ein Produktionsunternehmen nutzt eine selbst entwickelte Software zur Qualitätskontrolle. Die Daten in diesem System sind Gold wert — Fehlermuster, Prozessparameter, historische Trends. Ein KI-Assistent, der auf diese Daten zugreifen kann, könnte Produktionsleitern in Echtzeit Handlungsempfehlungen geben. Doch kein vorgefertigter MCP Server kennt dieses proprietäre System. Die Lösung: Ein massgeschneiderter MCP Server, der die Schnittstelle zwischen der Qualitätssoftware und der KI-Welt bildet.
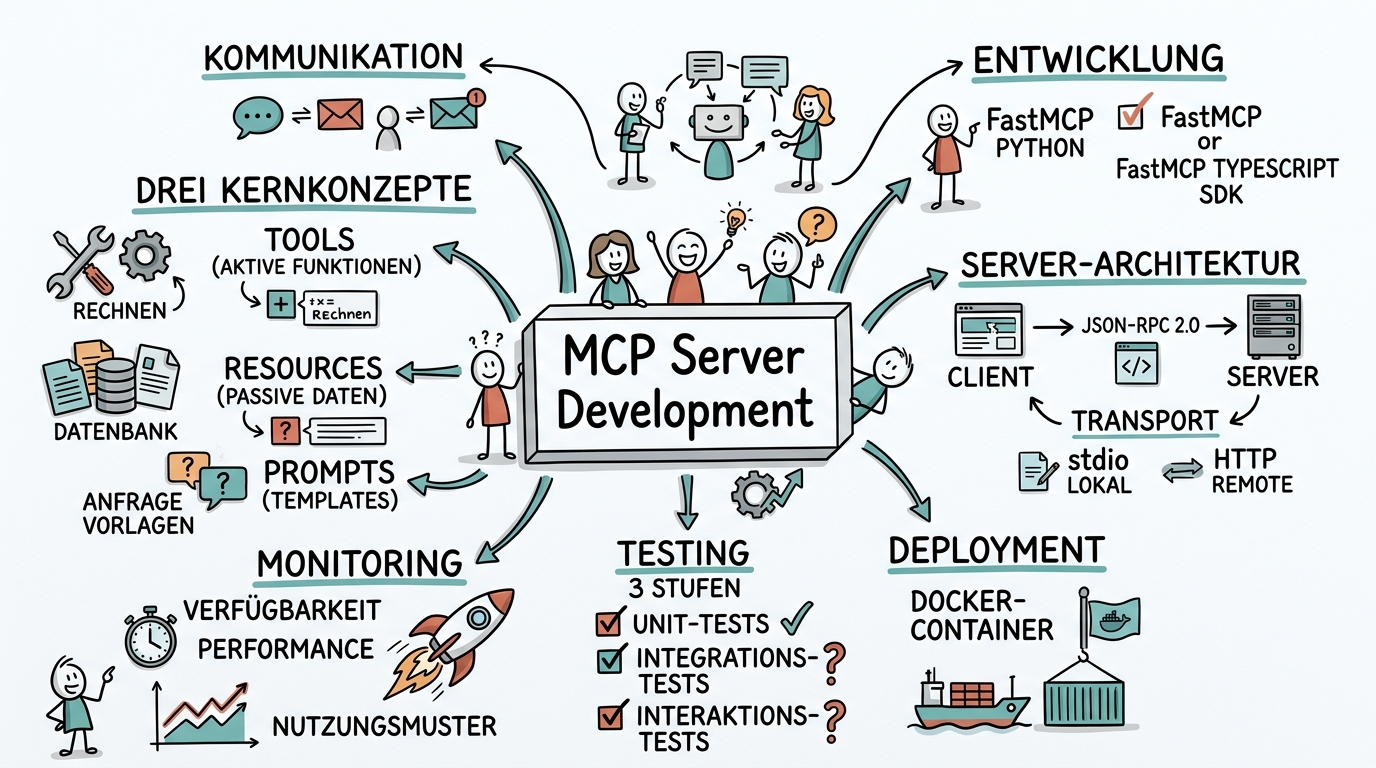
Die Architektur von MCP basiert auf einem klaren Prinzip: Der MCP Host — also die KI-Anwendung wie Claude Desktop oder Cursor — enthält einen MCP Client, der über standardisierte JSON-RPC-2.0-Nachrichten mit externen MCP Servern kommuniziert. Der Server stellt dem Modell Werkzeuge, Ressourcen und Prompts zur Verfügung, die es nutzen kann. Diese Trennung zwischen Client und Server bedeutet, dass ein einmal entwickelter MCP Server mit jeder MCP-kompatiblen KI-Anwendung funktioniert — unabhängig davon, ob diese von Anthropic, OpenAI oder Google stammt.
Die Einstiegshürde ist niedriger als viele denken. Mit Frameworks wie FastMCP für Python oder dem offiziellen TypeScript SDK lässt sich ein funktionsfähiger MCP Server in wenigen Stunden entwickeln. Die eigentliche Herausforderung liegt nicht in der MCP-Implementierung selbst, sondern in der sauberen Abstraktion des Zielsystems und dem durchdachten Design der Werkzeuge, die dem Modell zur Verfügung gestellt werden.
Lektion 2: Architektur und Grundkonzepte
Bevor Sie Ihren ersten MCP Server schreiben, müssen Sie die drei Kernkonzepte des Protokolls verstehen: Tools, Resources und Prompts. Tools sind Funktionen, die das Modell aktiv aufrufen kann — etwa eine Datenbankabfrage, das Erstellen eines Tickets oder das Versenden einer E-Mail. Jedes Tool hat einen Namen, eine Beschreibung und ein definiertes Input-Schema. Die Beschreibung ist dabei kritisch wichtig, denn das Modell entscheidet anhand dieser Beschreibung, wann es welches Tool einsetzt.
Resources sind passive Datenquellen, die das Modell lesen kann. Im Unterschied zu Tools lösen Resources keine Aktionen aus, sondern stellen Informationen bereit — etwa den Inhalt einer Datei, den aktüllen Status eines Systems oder eine Liste verfügbarer Datensätze. Resources haben eine URI und können statisch oder dynamisch sein. Ein statisches Resource könnte eine Konfigurationsdatei sein, ein dynamisches Resource der aktülle Lagerbestand.
Prompts schliesslich sind vorgefertigte Prompt-Templates, die der Server dem Nutzer anbieten kann. Sie sind besonders nützlich, wenn bestimmte Aufgaben immer wieder nach dem gleichen Muster ablaufen. Ein MCP Server für ein CRM-System könnte beispielsweise einen Prompt "Kundenprofil analysieren" anbieten, der automatisch alle relevanten Kundendaten lädt und dem Modell eine strukturierte Analysevorlage bereitstellt.
Die Kommunikation zwischen Client und Server erfolgt über zwei Transport-Varianten. Der stdio-Transport eignet sich für lokale Server, die als Subprocess gestartet werden — ideal für die Entwicklung und für Desktop-Anwendungen. Der HTTP-Transport mit Server-Sent Events ist für Remote-Server gedacht, die in der Cloud laufen und von mehreren Clients gleichzeitig genutzt werden. Die Wahl des Transports beeinflusst das Deployment, aber nicht die Funktionalität des Servers selbst.
Lektion 3: Ihren ersten MCP Server mit Python entwickeln
Der schnellste Weg zum eigenen MCP Server führt über Python und das FastMCP-Framework. FastMCP abstrahiert die Protokolldetails und lässt Sie sich auf die eigentliche Geschäftslogik konzentrieren. Die Installation ist denkbar einfach: Ein einziger pip-Befehl genügt, und Sie können mit dem Coding beginnen.
Ein minimaler MCP Server besteht aus nur wenigen Zeilen Code. Sie importieren FastMCP, erstellen eine Server-Instanz mit Namen und Beschreibung, und dekorieren Ihre Python-Funktionen mit dem Tool-Dekorator. FastMCP übernimmt automatisch die Generierung des JSON-Schemas aus den Python-Typ-Annotations und die Kommunikation mit dem Client. Was früher Hunderte Zeilen Boilerplate erforderte, reduziert sich auf die reine Geschäftslogik.
Nehmen wir ein konkretes Beispiel: Sie möchten einen MCP Server für Ihr internes Wiki bauen. Der Server soll drei Tools bereitstellen: Suche im Wiki, Artikel lesen und neuen Artikel erstellen. Für die Suche definieren Sie eine Funktion, die einen Suchbegriff entgegennimmt und eine Liste von Treffern zurückgibt. Für das Lesen eine Funktion, die eine Artikel-ID erwartet und den vollständigen Inhalt liefert. Für das Erstellen eine Funktion, die Titel und Inhalt entgegennimmt und den Artikel in der Datenbank speichert.
Die Beschreibungen Ihrer Tools verdienen besondere Aufmerksamkeit. Das KI-Modell liest diese Beschreibungen, um zu entscheiden, welches Tool es für eine Aufgabe einsetzt. Eine Beschreibung wie "Sucht im Wiki" ist zu vage — besser ist "Durchsucht das interne Unternehmens-Wiki nach Artikeln. Nutze dieses Tool, wenn der Nutzer nach internem Wissen, Prozessdokumentationen oder Unternehmensrichtlinien fragt." Je präziser die Beschreibung, desto zuverlässiger wählt das Modell das richtige Tool.
Lektion 4: Fortgeschrittene Patterns und Fehlerbehandlung
Sobald Ihr erster Server läuft, stossen Sie schnell auf fortgeschrittene Anforderungen. Eine der wichtigsten ist die robuste Fehlerbehandlung. In der Produktionspraxis kann alles schiefgehen: Die Datenbank ist nicht erreichbar, der API-Schlüssel ist abgelaufen, die Eingabedaten sind ungültig. Ein professioneller MCP Server fängt all diese Fälle ab und liefert dem Modell verständliche Fehlermeldungen, mit denen es arbeiten kann.
Die beste Praxis ist, zwischen erwarteten und unerwarteten Fehlern zu unterscheiden. Ein erwarteter Fehler wäre, dass ein gesuchter Artikel nicht existiert — hier sollte der Server eine klare Meldung zurückgeben wie "Kein Artikel mit dieser ID gefunden. Mögliche Ursachen: Die ID ist falsch, oder der Artikel wurde gelöscht." Ein unerwarteter Fehler wäre ein Datenbankausfall — hier sollte der Server eine allgemeine Fehlermeldung zurückgeben und gleichzeitig intern ein Logging auslösen, damit das Problem behoben werden kann.
Ein weiteres fortgeschrittenes Pattern ist die Implementierung von Paginierung. Wenn ein Tool potenziell tausende Ergebnisse zurückliefern kann, dürfen Sie nicht alle auf einmal senden — das würde das Kontextfenster des Modells sprengen. Stattdessen implementieren Sie eine Paginierung: Das Tool liefert die ersten zehn Ergebnisse und einen Hinweis, dass weitere verfügbar sind. Das Modell kann dann bei Bedarf die nächste Seite anfordern.
Authentifizierung und Autorisierung sind in Unternehmensumgebungen unverzichtbar. Ihr MCP Server muss sicherstellen, dass nur berechtigte Nutzer auf bestimmte Tools zugreifen können. Die empfohlene Methode ist OAuth 2.1, wobei der MCP-Standard für 2026 eine standardisierte Authentifizierungs-Schicht definiert. In der Praxis bedeutet das: Der Server prüft bei jedem Aufruf, ob der anfragende Client die nötige Berechtigung hat, und lehnt unautorisierte Anfragen mit einer klaren Fehlermeldung ab.
Lektion 5: Testing und Deployment
Das Testen eines MCP Servers unterscheidet sich von klassischem Software-Testing, weil Sie nicht nur die technische Korrektheit prüfen müssen, sondern auch die Interaktion mit dem KI-Modell. Ein Tool kann technisch einwandfrei funktionieren, aber trotzdem schlecht sein — nämlich dann, wenn das Modell es falsch einsetzt, weil die Beschreibung missverständlich ist oder das Rückgabeformat ungünstig gewählt wurde.
Ein bewährter Testansatz ist das dreistufige Vorgehen: Zürst Unit-Tests für die einzelnen Tool-Funktionen, um die technische Korrektheit sicherzustellen. Dann Integrationstests, bei denen der Server gegen das echte Zielsystem getestet wird. Schliesslich Interaktionstests, bei denen Sie den Server in einer KI-Anwendung wie Claude Desktop einbinden und typische Nutzeranfragen durchspielen. Besonders die dritte Stufe ist entscheidend, denn hier zeigt sich, ob das Modell die Tools korrekt und zuverlässig einsetzt.
Für das Deployment haben Sie mehrere Optionen. Der einfachste Weg ist der lokale Betrieb über stdio — der Server wird als Subprocess der KI-Anwendung gestartet und läuft auf dem gleichen Rechner. Für Teams und Unternehmen ist ein Remote-Deployment sinnvoller: Der Server läuft als Docker-Container in der Cloud, erreichbar über HTTPS, gesichert durch Authentifizierung und überwacht durch Monitoring. Die MCP-Roadmap 2026 legt grossen Wert auf Stateless-Architekturen, die ein horizontales Skalieren hinter Load Balancern ermöglichen.
Das Monitoring im Produktionsbetrieb umfasst drei Dimensionen: Verfügbarkeit, also ob der Server erreichbar ist und antwortet. Performance, also wie schnell die Tools reagieren — lange Antwortzeiten führen zu schlechter Nutzererfahrung. Und Nutzungsmuster, also welche Tools wie oft aufgerufen werden und welche Fehler auftreten. Diese Daten sind Gold wert für die Weiterentwicklung: Sie zeigen, welche Tools unverzichtbar sind, welche selten genutzt werden und wo Verbesserungsbedarf besteht.
Lektion 6: Praxisprojekt — MCP Server für ein Unternehmenswiki
In diesem abschliessenden Praxisprojekt bauen wir Schritt für Schritt einen vollständigen MCP Server für ein Unternehmenswiki. Das Ziel: Ein KI-Assistent soll Mitarbeitern helfen, schnell die richtigen Informationen im internen Wiki zu finden, Zusammenfassungen zu erstellen und bei Bedarf neue Artikel anzulegen.
Der erste Schritt ist das Design der Tool-Landschaft. Nach Analyse der häufigsten Anfragen an das Wiki ergeben sich fünf Tools: Eine Volltextsuche, die relevante Artikel nach Stichwort findet. Eine Kategorie-Navigation, die alle Artikel einer bestimmten Kategorie auflistet. Ein Artikel-Reader, der den vollständigen Inhalt eines Artikels zurückgibt. Ein Zusammenfasser, der mehrere Artikel zu einem Thema zusammenfasst. Und ein Artikel-Ersteller, der neue Beiträge in das Wiki schreibt. Jedes Tool wird mit einer präzisen Beschreibung versehen, die dem Modell klar macht, wann welches Tool zum Einsatz kommen soll.
Der zweite Schritt ist die Implementierung der Datenschicht. Der Server benötigt eine Verbindung zum Wiki-Backend — in unserem Fall eine PostgreSQL-Datenbank mit einer Volltextsuch-Erweiterung. Die Datenschicht abstrahiert alle Datenbankzugriffe hinter sauberen Funktionen, die von den Tool-Handlern aufgerufen werden. Diese Trennung macht den Code testbar und ermöglicht es, das Datenbank-Backend später auszutauschen, ohne die Tool-Logik ändern zu müssen.
Der dritte Schritt ist das Deployment und die Integration. Der fertige Server wird als Docker-Container verpackt, mit Umgebungsvariablen für die Datenbank-Verbindung und den API-Schlüssel konfiguriert, und in der Unternehmens-Cloud deployed. In der Claude-Desktop-Konfiguration wird der Server als Remote-MCP-Server eingetragen, und ab sofort können alle Mitarbeiter über ihren KI-Assistenten auf das Wiki zugreifen. Das Ergebnis: Die durchschnittliche Suchzeit für interne Informationen sinkt von Minuten auf Sekunden.