Lernen Sie, wie Sie Ihre KI-Ausgaben um 40-70% senken: Model Routing, Prompt Caching, Batch-APIs und Cost Tracking mit Tools wie LiteLLM, Helicone und Langfuse.
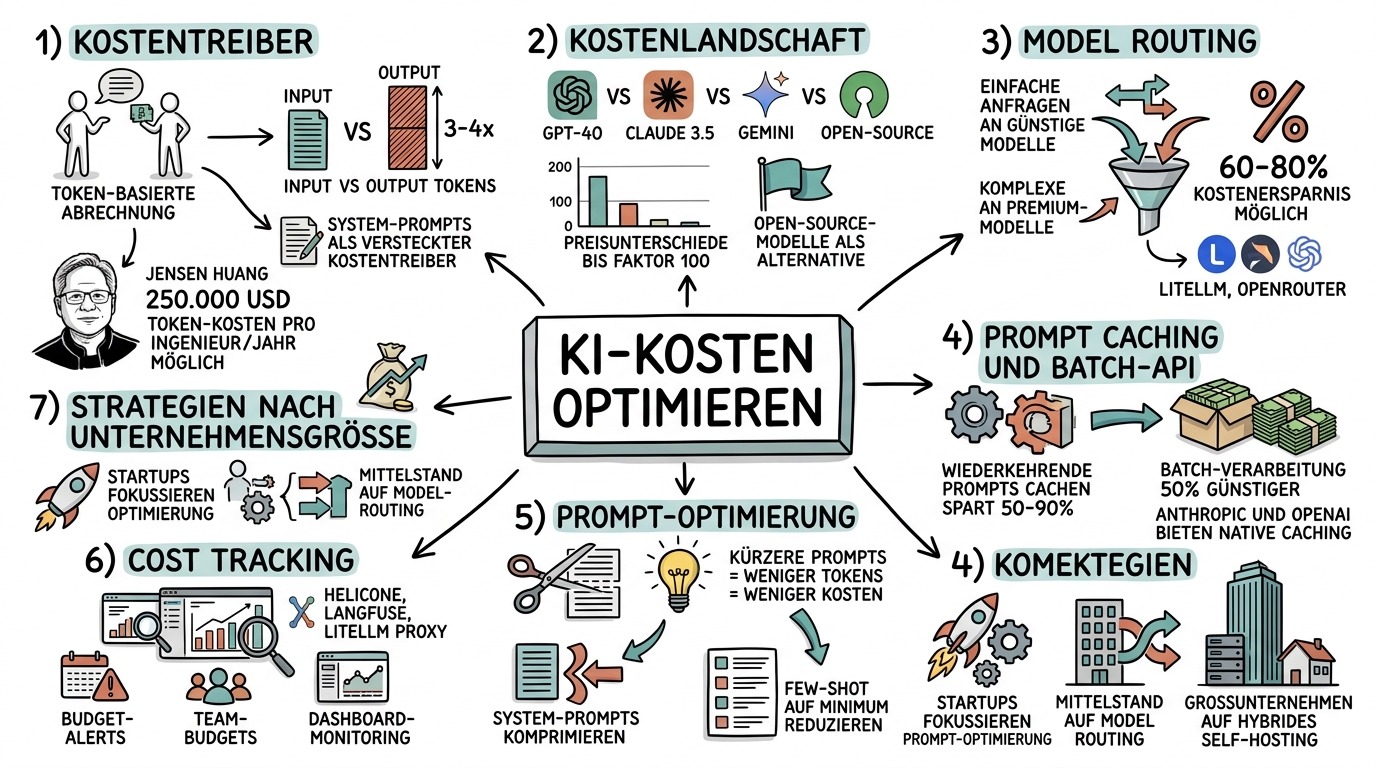
Visual Summary
Klicken zum Vergrößern
KI-Kosten optimieren und Token-Management
Lektion 1: Warum KI-Kosten schnell aus dem Ruder laufen
KI-Kosten außer Kontrolle — die versteckten Kostentreiber bei KI-APIs
Lernziel: Nach dieser Lektion können Sie die wichtigsten Kostentreiber bei der KI-API-Nutzung identifizieren und den Token-Verbrauch einer typischen Anwendung einschätzen.
Wer zum ersten Mal mit KI-APIs arbeitet, ist oft überrascht, wie schnell sich die Kosten summieren. Ein einzelner API-Call kostet vielleicht nur Bruchteile eines Cents, doch wenn Hunderte oder Tausende Anfragen pro Tag gestellt werden, entstehen schnell dreistellige Monatsrechnungen. Das Problem wird dadurch verschärft, dass viele Teams ihre KI-Nutzung nicht systematisch überwachen und erst am Monatsende beim Blick auf die Rechnung erschrecken.
Die Dimension dieser Kosten wird besonders deutlich, wenn man sich die Prognosen der Branchenführer anschaut. Jensen Huang, CEO von NVIDIA, hat in einem Interview beziffert, dass ein einzelner Ingenieur künftig bis zu 250.000 Dollar pro Jahr an Token-Kosten verursachen könnte. Das klingt abstrakt, wird aber greifbar, wenn man bedenkt, dass die nächste Generation von KI-Modellen auf deutlich teureren Chips trainiert wird. Die Schlussfolgerung ist klar: Wer heute nicht lernt, intelligent mit Token-Budgets umzugehen, wird morgen ein ernstes Kostenproblem haben.
Die Kostenstruktur von KI-APIs basiert auf sogenannten Tokens. Ein Token entspricht dabei etwa drei Viertel eines englischen Wortes, bei deutschen Texten liegt das Verhältnis etwas ungünstiger. Jeder API-Call hat Input-Tokens (die Anfrage) und Output-Tokens (die Antwort), wobei Output-Tokens typischerweise drei- bis viermal so teuer sind wie Input-Tokens. Hinzu kommen versteckte Kostentreiber wie System-Prompts, die bei jedem Call mitgesendet werden, oder lange Konversationshistorien, die den Context Window füllen.
Kostentreiber
Beschreibung
Typischer Anteil
System-Prompt
Wird bei jedem Call mitgesendet
20-40% der Input-Tokens
Konversationshistorie
Wächst mit jeder Nachricht
30-50% bei langen Chats
Output-Tokens
3-4x teurer als Input
Größter Kostenblock
Redundante Kontexte
Gleiche Dokumente wiederholt senden
Vermeidbar durch Caching
Ein typisches Beispiel verdeutlicht die Dynamik: Ein mittelständisches Unternehmen nutzt einen KI-Chatbot für den Kundenservice. Jede Konversation umfasst durchschnittlich fünf Nachrichten mit jeweils 500 Token System-Prompt. Bei 200 Gesprächen pro Tag und dem Einsatz von GPT-4o-Class-Modellen entstehen monatliche Kosten von mehreren Tausend Euro, obwohl 80 Prozent der Anfragen auch von einem deutlich günstigeren Modell beantwortet werden könnten. Genau hier setzt professionelles KI-Kostenmanagement an.
> Praxistipp: Berechnen Sie als ersten Schritt Ihre aktüllen Token-Kosten. Multiplizieren Sie die durchschnittliche Anzahl der Tokens pro Anfrage mit der Anzahl der täglichen Anfragen und dem Preis pro Token Ihres genutzten Modells. Oft liefert diese einfache Rechnung bereits den Impuls für sofortiges Handeln.
Kernpunkte dieser Lektion:
Token sind die Währung der KI-Welt, und Output-Tokens kosten ein Vielfaches der Input-Tokens
System-Prompts und Konversationshistorien sind die größten versteckten Kostentreiber
Bereits eine einfache Kostenrechnung deckt erhebliches Einsparpotenzial auf
Reflexionsfragen:
Wie viele API-Calls macht Ihre Anwendung pro Tag, und kennen Sie die durchschnittliche Token-Anzahl pro Call?
Welcher Anteil Ihrer KI-Anfragen könnte von einem günstigeren Modell beantwortet werden, ohne dass Nutzer einen Unterschied bemerken?
Lektion 2: Die Kostenlandschaft der großen Anbieter verstehen
Kostenvergleich der großen KI-Anbieter — OpenAI, Anthropic, Google und Open Source
Lernziel: Nach dieser Lektion können Sie die Preismodelle der führenden KI-Anbieter vergleichen und den Break-Even-Point zwischen API-Nutzung und Self-Hosting berechnen.
Der KI-Markt hat sich 2025 und 2026 stark ausdifferenziert, und die Preisunterschiede zwischen den Anbietern sind enorm. Wer die Kostenlandschaft versteht, kann allein durch die Wahl des richtigen Modells für den richtigen Anwendungsfall erheblich sparen. Die drei großen Anbieter verfolgen dabei unterschiedliche Preisstrategien, die sich gezielt nutzen lassen.
Ein wichtiger Trend zeichnet sich dabei ab: Die Modelle werden mit jeder Generation besser, aber nicht exponentiell teurer. Das bedeutet, dass man für den gleichen Preis immer leistungsfähigere Modelle bekommt. Die eigentliche Entscheidung liegt daher nicht mehr bei der Frage "Welches Modell ist das beste?", sondern bei "Welches Modell ist für diese Aufgabe kosteneffizient genug?" und "Sollte ich ein Modell lokal hosten oder über die API nutzen?"
OpenAI bietet mit GPT-4o ein leistungsstarkes Allround-Modell an, das für die meisten Business-Anwendungen ausreicht. Daneben gibt es mit GPT-4o-mini eine deutlich günstigere Variante, die bei einfacheren Aufgaben kaum Qualitätseinbußen zeigt. Anthropic positioniert sich mit Claude als Premium-Anbieter für komplexe Aufgaben, bietet aber mit Claude Haiku ein extrem kosteneffizientes Modell für Standardaufgaben. Google hat mit Gemini 2.5 Pro und Flash eine ähnliche Staffelung eingeführt, wobei Flash besonders beim Preis-Leistungs-Verhältnis überzeugt.
Daneben wächst der Open-Source-Markt rasant. Modelle wie Llama 3, Mistral und Phi lassen sich lokal oder auf eigenen Servern betreiben, wodurch nur Infrastrukturkosten anfallen. Für Unternehmen mit hohem Volumen kann Self-Hosting ab einer bestimmten Schwelle günstiger sein als API-Nutzung. Der Knackpunkt liegt in der Berechnung des Break-Even-Points: Ab welchem monatlichen Token-Volumen lohnt sich die eigene Infrastruktur? Als Faustregel gilt, dass Self-Hosting ab etwa 50 Millionen Tokens pro Monat wirtschaftlich wird, wenn die notwendige GPU-Infrastruktur bereits vorhanden ist.
> Praxistipp: Erstellen Sie eine Vergleichstabelle mit Ihren drei häufigsten Anwendungsfällen. Berechnen Sie für jeden Fall die monatlichen Kosten bei mindestens zwei verschiedenen Anbietern. Oft ergibt sich allein aus dieser Analyse eine Einsparung von 20-30%.
Kernpunkte dieser Lektion:
Die Preisunterschiede zwischen Frontier- und Budget-Modellen sind erheblich, bei oft geringem Qualitätsunterschied für Standardaufgaben
Self-Hosting lohnt sich ab ca. 50 Millionen Tokens pro Monat
Die richtige Modellwahl pro Anwendungsfall ist der einfachste Hebel zur Kostenreduktion
Reflexionsfragen:
Nutzen Sie aktüll für alle Aufgaben dasselbe KI-Modell? Welche Aufgaben könnten von einem günstigeren Modell übernommen werden?
Wie hoch ist Ihr monatliches Token-Volumen, und ab wann würde sich Self-Hosting für Sie rechnen?
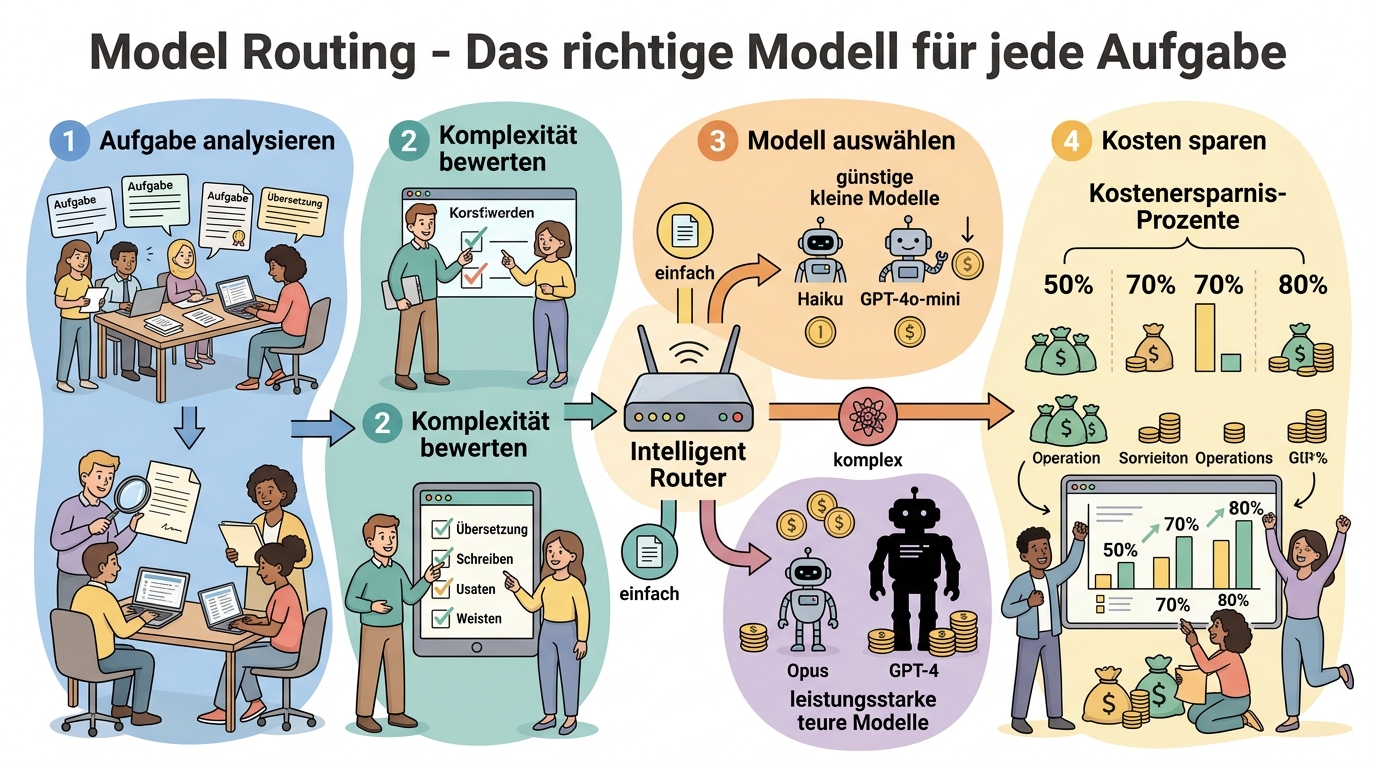
Lektion 3: Model Routing, das richtige Modell für jede Aufgabe
Model Routing — intelligente Aufgabenverteilung an verschiedene KI-Modelle
Lernziel: Nach dieser Lektion können Sie ein Model-Routing-System konzipieren und die erwarteten Kosteneinsparungen für Ihre Anwendung berechnen.
Die wirksamste Strategie zur Kostensenkung ist Model Routing: Statt jede Anfrage an das teuerste und leistungsfähigste Modell zu senden, wird automatisch das passende Modell für die jeweilige Aufgabe ausgewählt. In der Praxis können damit 60 bis 80 Prozent der Kosten eingespart werden, ohne dass die Nutzer einen spürbaren Qualitätsverlust erleben.
Das Grundprinzip ist einfach: Ein vorgeschalteter Classifier oder ein regelbasiertes System bewertet die eingehende Anfrage und leitet sie an das passende Modell weiter. Eine einfache FAQ-Frage wird von einem kleinen, günstigen Modell beantwortet, während eine komplexe Analyse-Aufgabe an das Frontier-Modell geht. Dabei ist es wichtig zu verstehen, dass die Rolle des Menschen sich fundamental verändert. Statt Code Zeile für Zeile zu schreiben, geht es heute darum, Ergebnisse zu spezifizieren und das Intelligenz-Budget zu verwalten, das diese Ergebnisse erzeugt. Model Routing ist ein konkretes Werkzeug für genau diese neue Aufgabe.
Tools wie OpenRouter und LiteLLM machen dieses Routing technisch einfach umsetzbar. OpenRouter bietet einen einheitlichen API-Endpunkt, über den Dutzende Modelle verschiedener Anbieter angesteuert werden können, inklusive automatischem Fallback bei Ausfällen. LiteLLM ermöglicht es, über eine einzige Schnittstelle zwischen OpenAI, Anthropic, Google und Open-Source-Modellen zu wechseln, ohne den Anwendungscode ändern zu müssen.
Anfrage-Typ
Empfohlenes Modell
Typische Kosten
Einsparung vs. Frontier
FAQ, einfache Fragen
GPT-4o-mini / Haiku
~0,001 ct/Anfrage
90-95%
Produktberatung, Zusammenfassungen
Claude Sonnet / Gemini Pro
~0,01 ct/Anfrage
50-70%
Komplexe Analyse, Kreativaufgaben
GPT-4o / Claude Opus
~0,05 ct/Anfrage
Referenzwert
Einfache Klassifikation
Lokales Modell (Phi/Mistral)
~0 (nur Infrastruktur)
~100%
Ein Praxisbeispiel aus dem E-Commerce zeigt das Potenzial: Ein Online-Händler nutzte zunächst ausschließlich GPT-4o für seinen Produktberater. Nach der Einführung von Model Routing werden einfache Produktfragen (Verfügbarkeit, Lieferzeit, Retouren) von GPT-4o-mini beantwortet, Produktvergleiche und Beratung von Claude Sonnet, und nur komplexe Reklamationsfälle von GPT-4o. Die monatlichen Kosten sanken von 4.200 Euro auf 890 Euro bei gleichbleibender Kundenzufriedenheit.
> Praxistipp: Beginnen Sie mit einer einfachen Regel: Klassifizieren Sie Ihre Anfragen in drei Kategorien (einfach, mittel, komplex) und weisen Sie jeder Kategorie ein passendes Modell zu. Schon diese grobe Einteilung senkt die Kosten typischerweise um 50%.
Kernpunkte dieser Lektion:
Model Routing senkt die Kosten um 60-80% bei gleichbleibender Qualität
Tools wie OpenRouter und LiteLLM machen die Implementierung technisch einfach
Bereits eine einfache Drei-Stufen-Klassifikation bringt erhebliche Einsparungen
Praxisübung: Erstellen Sie eine Liste Ihrer fünf häufigsten KI-Anfrage-Typen. Ordnen Sie jedem Typ ein geeignetes Modell zu und berechnen Sie die erwartete Kostenreduktion. Nutzen Sie dafür die aktüllen Preislisten der Anbieter.
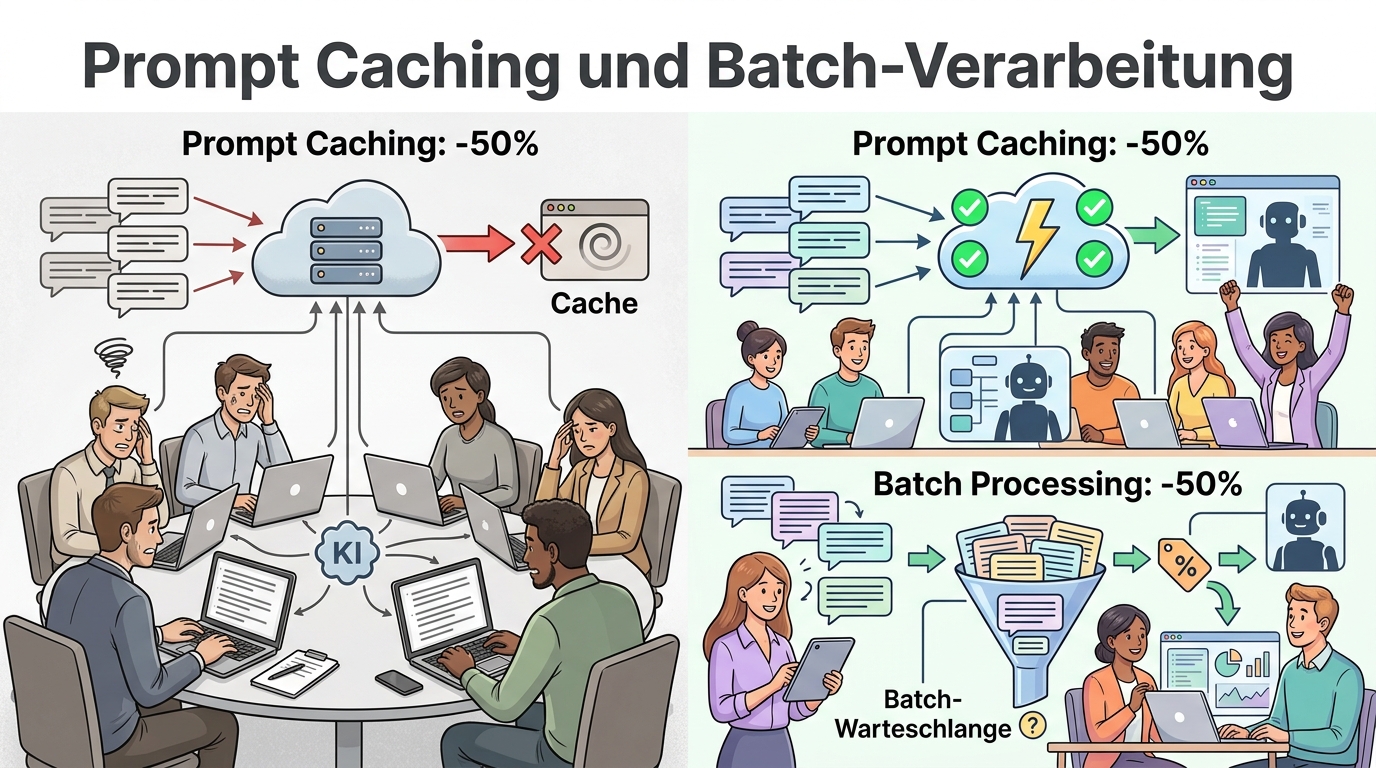
Lektion 4: Prompt Caching und Batch-Verarbeitung
Prompt Caching und Batch-Verarbeitung — zwei Hebel für massive Kostensenkung
Lernziel: Nach dieser Lektion können Sie Prompt Caching und Batch-APIs in Ihren KI-Anwendungen implementieren und die Einsparungen quantifizieren.
Prompt Caching ist eine der am meisten unterschätzten Optimierungstechniken. Die Idee ist bestechend einfach: Wenn viele API-Calls den gleichen System-Prompt oder ähnliche Präfixe verwenden, muss das Modell diesen Teil nicht jedes Mal neu verarbeiten. Anthropic bietet mit Prompt Caching für Claude eine native Lösung an, die die Kosten für den gecachten Teil um bis zu 90 Prozent reduziert.
In der Praxis funktioniert das so: Der System-Prompt und häufig verwendete Kontextdokumente werden als Cache-Prefix definiert. Bei nachfolgenden Anfragen erkennt die API den gecachten Teil und berechnet nur die neuen Tokens zum vollen Preis. Für Anwendungen mit langen System-Prompts oder RAG-Systeme, die regelmäßig dieselben Dokumente als Kontext mitgeben, ist der Einspareffekt enorm. Ein RAG-System, das bei jeder Anfrage 3.000 Token Kontext mitsendet, spart bei 10.000 Anfragen pro Tag allein durch Caching mehrere Hundert Euro monatlich.
Technik
Ersparnis
Latenz
Idealer Einsatz
Prompt Caching
bis 90% auf gecachte Tokens
Gleichbleibend
Wiederkehrende System-Prompts, RAG
Batch-API
50% auf alle Tokens
Höher (bis 24h)
Nachtverarbeitung, Massendaten
Kombination
bis 95%
Variabel
Hohe Volumina mit wiederkehrenden Mustern
Die Batch-API ist eine weitere wichtige Stellschraube. Sowohl OpenAI als auch Anthropic bieten Batch-Endpunkte an, bei denen Anfragen gesammelt und asynchron verarbeitet werden. Der Preis liegt typischerweise bei 50 Prozent des regulären API-Preises. Der Nachteil ist die höhere Latenz: Batch-Anfragen werden innerhalb von 24 Stunden bearbeitet, eignen sich also nicht für Echtzeit-Anwendungen. Ideal sind sie jedoch für Aufgaben wie die nächtliche Verarbeitung von Kundenfeedback, die Kategorisierung von E-Mails oder die Generierung von Produktbeschreibungen.
Ein konkretes Szenario zeigt den kombinierten Effekt: Ein Unternehmen verarbeitet jede Nacht 5.000 Support-Tickets mit KI-gestützter Kategorisierung und Zusammenfassung. Durch den Einsatz der Batch-API spart es 50 Prozent gegenüber dem regulären Preis. Zusätzlich nutzt es Prompt Caching für den identischen Kategorisierungs-Prompt. In Summe sinken die Kosten um über 80 Prozent gegenüber der ursprünglichen Implementierung.
> Praxistipp: Prüfen Sie, welche Ihrer KI-Aufgaben nicht in Echtzeit beantwortet werden müssen. Jede Aufgabe, die auch eine Stunde später fertig sein darf, ist ein Kandidat für die Batch-API und damit für 50% Kostensenkung.
Kernpunkte dieser Lektion:
Prompt Caching spart bis zu 90% auf wiederkehrende Prompt-Teile
Die Batch-API halbiert die Kosten für nicht-zeitkritische Aufgaben
Die Kombination beider Techniken ermöglicht Einsparungen von über 80%
Reflexionsfragen:
Welche Ihrer KI-Aufgaben verwenden immer denselben System-Prompt und könnten von Caching profitieren?
Welche Prozesse laufen bei Ihnen nachts oder zeitversetzt und wären Kandidaten für die Batch-API?
Lektion 5: Prompt-Optimierung als Kostenhebel
Prompt-Optimierung — vorher und nachher im Token-Verbrauch
Lernziel: Nach dieser Lektion können Sie Prompts systematisch auf Token-Effizienz analysieren und um 30-50% komprimieren, ohne die Antwortqualität zu beeinträchtigen.
Weniger beachtet, aber hocheffektiv ist die Optimierung der Prompts selbst. Jedes überflüssige Wort im Prompt kostet Geld, und viele Prompts enthalten redundante Anweisungen, unnötige Beispiele oder zu ausführliche Kontextinformationen. Professionelle Prompt-Komprimierung kann die Token-Anzahl um 30 bis 50 Prozent reduzieren, ohne die Qualität der Antworten zu beeinträchtigen.
Der erste Schritt ist eine Bestandsaufnahme: Welche Prompts werden am häufigsten verwendet und wie lang sind sie? Oft zeigt sich, dass System-Prompts über die Zeit gewachsen sind und Anweisungen enthalten, die sich widersprechen oder längst irrelevant sind. Ein reales Beispiel verdeutlicht das Problem: Eine KI-Pipeline verarbeitet mehrere lange Konversationen pro Nutzer, führt eine Analyse über Dutzende Dimensionen durch und generiert eine vollständig personalisierte Ausgabe. Die Kosten pro Nutzer betragen dabei weniger als 25 Cent. Das zeigt, dass selbst komplexe Pipelines kosteneffizient betrieben werden können, wenn die Prompts intelligent strukturiert sind.
Eine strukturierte Überarbeitung kann den Token-Verbrauch drastisch senken. Dabei hilft es, Prompts modular aufzubauen: Ein kompakter Basis-Prompt wird je nach Anfrage-Typ um spezifische Module ergänzt, statt immer den vollständigen Prompt zu senden. Stellen Sie sich das wie einen Baukasten vor, bei dem Sie nur die Teile verwenden, die für die aktülle Aufgabe relevant sind.
Optimierungstechnik
Einsparung
Aufwand
Qualitätsrisiko
Redundanzen entfernen
15-25%
Gering
Keines
Modularer Prompt-Aufbau
25-40%
Mittel
Gering
Ausgabelänge begrenzen
20-50%
Gering
Gering bei klaren Vorgaben
JSON-Mode statt Fließtext
30-60%
Mittel
Keines bei strukturierten Daten
Ein weiterer Hebel ist die gezielte Steuerung der Ausgabelänge. Viele Anwendungen fordern das Modell auf, ausführliche Antworten zu generieren, obwohl eine knappe Antwort ausreichen würde. Die Anweisung "Antworte in maximal drei Sätzen" spart nicht nur Output-Tokens, sondern verbessert oft sogar die Nutzererfahrung. Für strukturierte Ausgaben empfiehlt sich zudem die Verwendung von JSON-Mode oder Tool-Use, da diese Formate typischerweise kompakter sind als Fließtext-Antworten.
> Praxistipp: Nehmen Sie Ihren längsten System-Prompt und versuchen Sie, ihn auf die Hälfte der Token-Anzahl zu kürzen. Testen Sie die gekürzte Version mit 20 realen Anfragen. In den meisten Fällen werden Sie keinen Qualitätsunterschied feststellen.
Kernpunkte dieser Lektion:
Prompt-Komprimierung spart 30-50% der Token-Kosten bei minimalem Qualitätsverlust
Modulare Prompt-Architekturen vermeiden das Senden unnötiger Kontexte
Die Begrenzung der Ausgabelänge ist ein schneller Hebel mit doppeltem Nutzen
Praxisübung: Wählen Sie einen System-Prompt aus Ihrer Anwendung. Zählen Sie die aktülle Token-Anzahl (z.B. mit dem OpenAI Tokenizer). Identifizieren Sie drei Bereiche, die gekürzt oder modularisiert werden können. Setzen Sie die Änderung um und vergleichen Sie die Ergebnisse.
Lektion 6: Cost Tracking und Monitoring aufsetzen
KI-Kosten-Dashboard — Monitoring und Tracking im Überblick
Lernziel: Nach dieser Lektion können Sie ein KI-Kostenmonitoring mit Tools wie Helicone oder Langfuse implementieren und datenbasierte Optimierungsentscheidungen treffen.
Ohne Transparenz über die tatsächlichen Kosten ist jede Optimierung ein Blindflug. Professionelles KI-Kostenmanagement erfordert ein Monitoring-System, das Kosten nach Anwendung, Modell, Team und Zeitraum aufschlüsselt. Erst mit diesen Daten lassen sich fundierte Entscheidungen über Optimierungsmaßnahmen treffen.
Dabei ist es hilfreich, sich an etablierten Setups zu orientieren. Erfahrene Anwender bauen ihre KI-Systeme auf drei Säulen auf: Building (Entwicklung mit Tools wie Claude Code), Automation (automatisierte Prozesse, etwa mit n8n) und Operation (tägliche operative Arbeit). Für jede dieser Säulen braucht es eigene Kosten-Transparenz, denn die Kostentreiber unterscheiden sich fundamental. Ein Entwicklungs-Tool wie Claude Code kann mit einer Flatrate von 200 Dollar pro Monat abgedeckt sein, während Automationsprozesse mit jeder Ausführung variable Kosten erzeugen.
Tools wie Helicone und Langfuse haben sich als De-facto-Standards für KI-Observability etabliert. Helicone fungiert als Proxy zwischen der eigenen Anwendung und der KI-API und protokolliert dabei jeden Call mit Kosten, Latenz, Token-Verbrauch und Erfolgsrate. Das Dashboard zeigt auf einen Blick, welche Anwendungen die meisten Kosten verursachen und wo Optimierungspotenzial liegt. Langfuse geht einen Schritt weiter und bietet zusätzlich Tracing für komplexe LLM-Pipelines, sodass auch bei mehrstufigen Agenten-Workflows nachvollziehbar wird, wo die Kosten entstehen.
Tool
Typ
Stärke
Ideal für
Helicone
Proxy-basiert
Einfache Integration, Kosten-Dashboard
Schneller Einstieg, Einzelanwendungen
Langfuse
Tracing-Plattform
Pipeline-Tracing, Evaluierung
Komplexe Agent-Workflows
LiteLLM
Gateway + Proxy
Multi-Provider, Budgets, Rate Limits
Teams mit mehreren Modellen
Provider-Dashboard
Nativ
Kein Setup nötig
Erste Orientierung
Ein bewährtes Vorgehen für die Einführung eines Monitoring-Systems sieht so aus: Im ersten Monat werden alle KI-Calls ohne Änderungen protokolliert, um eine Baseline zu schaffen. Im zweiten Monat identifiziert man die Top-5-Kostentreiber und implementiert gezielte Optimierungen (Model Routing, Caching, Prompt-Komprimierung). Ab dem dritten Monat werden Budgets pro Team oder Anwendung definiert und automatische Alerts eingerichtet, die bei Überschreitung warnen. Unternehmen, die diesen Prozess durchlaufen, berichten typischerweise von Kostensenkungen zwischen 40 und 70 Prozent.
> Praxistipp: Starten Sie mit Helicone. Die Integration erfordert nur eine Zeile Code-Änderung (den API-Endpunkt auf den Helicone-Proxy umstellen). Innerhalb einer Woche haben Sie ein klares Bild Ihrer Kostenstruktur.
Kernpunkte dieser Lektion:
Ohne Monitoring ist Kostenoptimierung Blindflug
Helicone und Langfuse sind die führenden Tools für KI-Observability
Der Drei-Monats-Plan (Baseline, Optimierung, Budgets) ist ein bewährter Einstieg
Reflexionsfragen:
Wissen Sie heute, welche Ihrer KI-Anwendungen die höchsten Kosten verursacht? Falls nicht: Was hindert Sie daran, ein Monitoring aufzusetzen?
Wie würden Sie die KI-Kosten in Ihrem Unternehmen auf Teams oder Projekte verteilen, um Verantwortlichkeit zu schaffen?
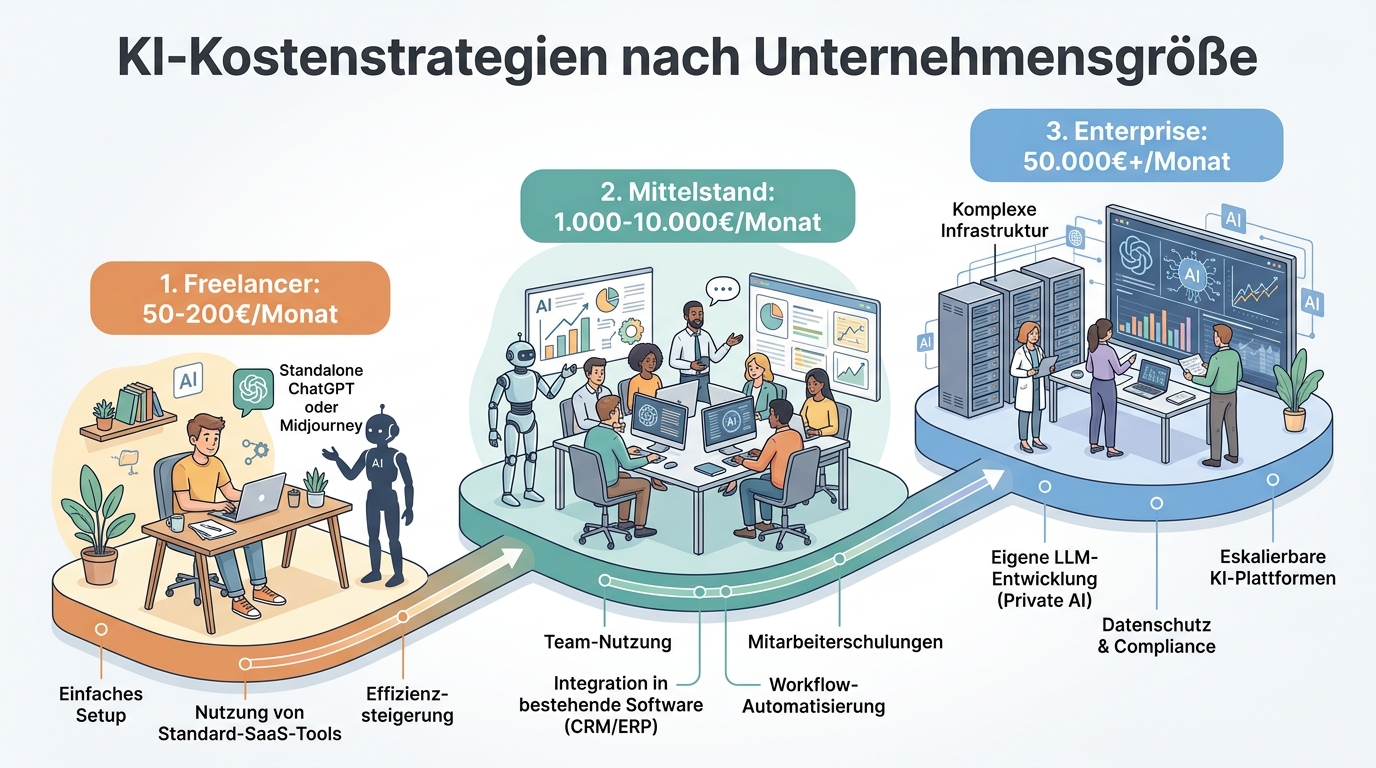
Lektion 7: Strategien für verschiedene Unternehmensgrößen
KI-Kostenstrategien nach Unternehmensgröße — vom Freelancer bis zum Enterprise
Lernziel: Nach dieser Lektion können Sie eine maßgeschneiderte KI-Kostenstrategie für Ihr Unternehmen entwickeln und einen konkreten Optimierungsfahrplan erstellen.
Die optimale Kostenstrategie hängt stark von der Unternehmensgröße und dem Nutzungsvolumen ab. Was für ein Startup mit 1.000 API-Calls pro Tag sinnvoll ist, unterscheidet sich fundamental von den Anforderungen eines Konzerns mit Millionen täglicher Anfragen. Die gute Nachricht ist: In jeder Größenklasse gibt es erhebliches Einsparpotenzial.
Für kleine Teams und Startups empfiehlt sich ein pragmatischer Ansatz: Ein günstiges Standardmodell wie Claude Haiku oder GPT-4o-mini für die Mehrzahl der Aufgaben, ergänzt durch ein Frontier-Modell für komplexe Fälle. Einfaches Logging über die Provider-Dashboards reicht in dieser Phase meist aus. Der Fokus sollte auf Prompt-Optimierung liegen, da dies den größten Hebel bei geringem Aufwand bietet. Viele Startups übersehen zudem die großzügigen Free Tiers der Anbieter: Google bietet für Gemini Flash ein kostenloses Kontingent, das für Prototyping und kleine Anwendungen ausreichen kann. Auch ein günstiger VPS (Virtual Private Server) ab etwa 5 Euro im Monat kann ausreichen, um Automations-Tools wie n8n selbst zu hosten und damit Cloud-Kosten zu vermeiden.
Mittelständische Unternehmen profitieren am meisten von Model Routing und Prompt Caching. Die Investition in ein Tool wie LiteLLM oder OpenRouter amortisiert sich typischerweise innerhalb weniger Wochen. Zusätzlich lohnt sich die Einführung eines zentralen KI-Gateways, das alle API-Calls bündelt und zentrale Policies durchsetzt. So lässt sich beispielsweise festlegen, dass bestimmte Abteilungen nur bestimmte Modelle nutzen dürfen oder dass ein monatliches Budget nicht überschritten werden kann.
Großunternehmen und Konzerne stehen vor der Frage des Self-Hostings. Ab einem bestimmten Volumen kann es wirtschaftlicher sein, Open-Source-Modelle auf eigener Infrastruktur zu betreiben. Dabei sind jedoch die versteckten Kosten zu beachten: GPU-Hardware, Strom, Kühlung, Personal für Betrieb und Wartung sowie der Aufwand für Modell-Updates. Eine hybride Strategie kombiniert Self-Hosting für Standardaufgaben mit API-Nutzung für Spitzenlasten und Frontier-Modell-Zugriff.
Unternehmensgröße
Erste Maßnahme
Wichtigstes Tool
Erwartete Einsparung
Startup / kleines Team
Prompt-Optimierung + günstiges Modell
Provider-Dashboard
20-40%
Mittelstand
Model Routing + Caching
LiteLLM / OpenRouter + Helicone
40-70%
Großunternehmen
Hybrides Self-Hosting + Gateway
LiteLLM Gateway + Langfuse
50-80%
> Praxistipp: Unabhängig von der Unternehmensgröße gilt: Starten Sie mit der Transparenz. Bevor Sie optimieren, müssen Sie wissen, wo Ihre Kosten anfallen. Der erste Schritt ist immer ein Monitoring-Tool, auch wenn es nur das Provider-Dashboard ist.
Kernpunkte dieser Lektion:
Die optimale Strategie hängt vom Nutzungsvolumen und der Unternehmensgröße ab
Startups profitieren am meisten von Prompt-Optimierung, der Mittelstand von Model Routing
Eine hybride Strategie (Self-Hosting + API) ist für Großunternehmen oft der kosteneffizienteste Weg
Abschlussübung: Erstellen Sie einen 90-Tage-Optimierungsplan für Ihr Unternehmen. Definieren Sie für jeden Monat ein konkretes Ziel: Monat 1 (Transparenz schaffen), Monat 2 (Top-3-Kostentreiber optimieren), Monat 3 (Budgets und Alerts einführen). Notieren Sie die erwarteten Einsparungen und messen Sie nach 90 Tagen die tatsächlichen Ergebnisse.