KI-Destillation: Wenn Modelle gestohlen werden
Einleitung
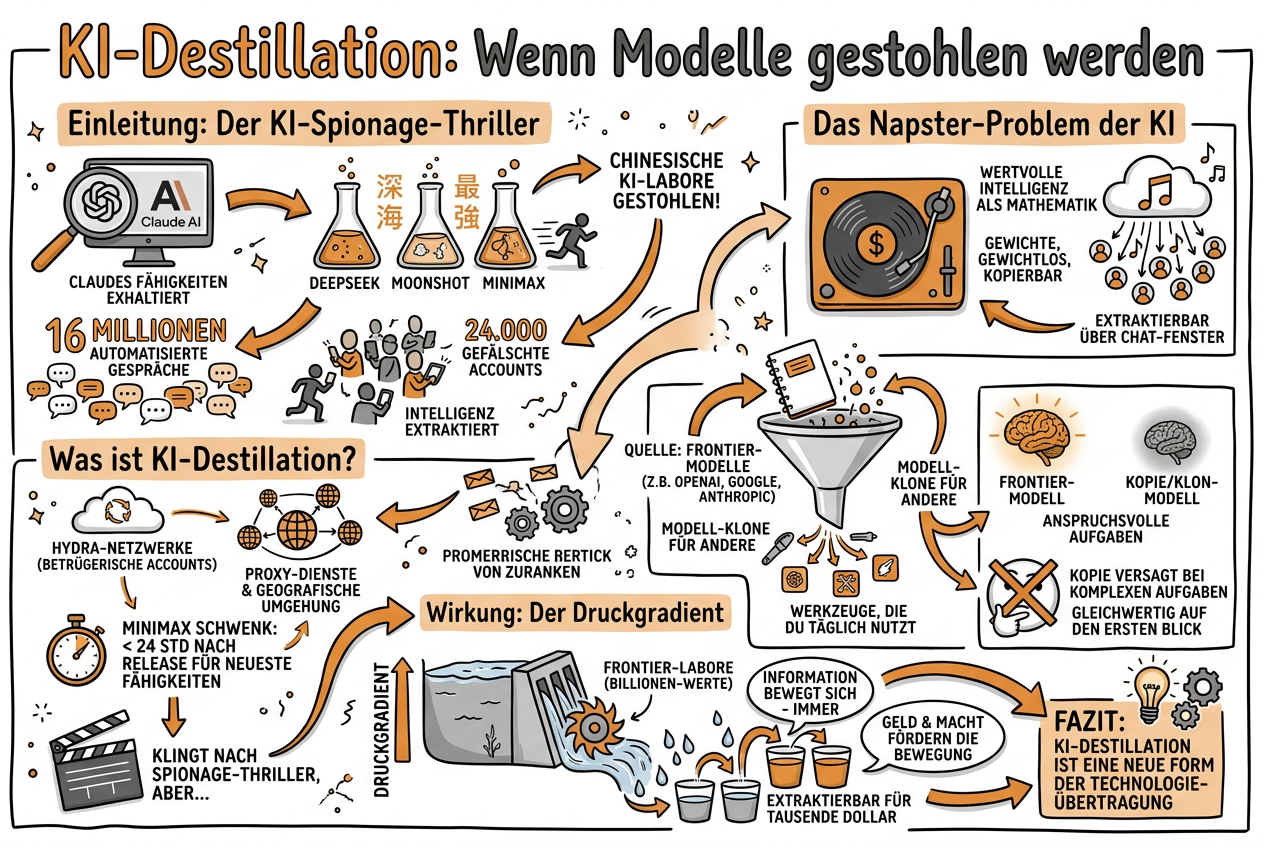
Drei chinesische KI-Labore haben söben dabei erwischt, wie sie Claudes Fähigkeiten gestohlen haben. DeepSeek, Moonshot und Minimax führten 16 Millionen automatisierte Gespräche mit Claude über 24.000 gefälschte Accounts, um dessen Intelligenz zu extrahieren. Hydra-Netzwerke aus betrügerischen Accounts, Proxy-Dienste zur Umgehung geografischer Beschränkungen -- und im Fall von Minimax ein Schwenk innerhalb von 24 Stunden nach einem neuen Modell-Release, um die neuesten Fähigkeiten abzugreifen.
Klingt nach Spionage-Thriller. Aber die eigentliche Geschichte ist grösser als ein Geopolitik-Krimi. Sie betrifft direkt die Werkzeuge, die du täglich nutzt -- und erklärt, warum manche KI-Modelle auf den ersten Blick gleichwertig aussehen, aber bei anspruchsvollen Aufgaben versagen.
Was ist KI-Destillation?
Das Napster-Problem der KI
Die wertvollste Intelligenz, die jemals von Unternehmen geschaffen wurde, ist als Mathematik gespeichert. Bei OpenAI, bei Google, bei Anthropic -- als Gewichte, gewichtlos, kopierbar, extrahierbar über ein Chat-Fenster.
Die Lücke zwischen dem, was in den Frontier-Laboren steckt, und dem, was alle anderen erreichen können, erzeugt einen Druckgradienten. Dieselbe Kraft, die Wasser bergab fliessen lässt. Wenn eine Seite Fähigkeiten besitzt, die potenziell Billionen wert sind, und die andere Seite sie für Tausende Dollar extrahieren kann, bewegt sich die Information -- immer.
Der Vergleich mit der Musikindustrie liegt nahe: Als Napster 1999 die Musikpiraterie demokratisierte und die Filmindustrie 2003 dasselbe erlebte, stoppte die Piraterie nicht. Sie verlangsamte sich. Die entscheidende Frage ist: Wie schnell ist diese Verlangsamung im Vergleich zum Fähigkeitsgewinn der Frontier-Modelle? Und wenn sich Modell-Fähigkeiten alle 90 Tage verdoppeln, ist das hochrelevant.
Wie Destillation funktioniert
Destillation erzeugt keine Kopie des Originalmodells. Sie erzeugt eine Kompression. Und diese Kompression hat -- wie ein verlustbehaftetes MP3 -- Eigenschaften, die für jeden relevant sind, der auf diesen Modellen reale Systeme aufbaut.
Geometrisch betrachtet: Ein Frontier-Modell wie Claude Opus 4.6 wird auf einem riesigen, diversen Datensatz über Monate hinweg trainiert. Das Ergebnis ist ein Modell, das einen hochdimensionalen Fähigkeitsraum besetzt. Es kann über Code nachdenken, mehrdeutige Anweisungen navigieren, Werkzeuge in neuen Kombinationen nutzen, Kohärenz über lange Workflows aufrechterhalten, sich von Fehlern erholen und seinen Ansatz anpassen, wenn ein Plan scheitert.
Ein destilliertes Modell wird dagegen auf einer Teilmenge der Ausgaben des Frontier-Modells trainiert. Es lernt, bestimmte Verhaltensweisen zu reproduzieren -- die, welche der Destillierer ausgewählt hat. Das Ergebnis: ein Modell, das bei diesen spezifischen Verhaltensweisen gut abschneidet, aber einen engeren Fähigkeitsraum besetzt. Es steigt schneller ab, sobald man die Trainingsverteilung verlässt.
Die Football-Analogie
Wenn du ein komplettes NFL-Football-Spiel schaust, siehst du jeden Spielzug -- plus viel Werbung. Wenn du nur die Highlights schaust, siehst du weniger Werbung, aber auch viel weniger vom eigentlichen Spiel. Nur die Ausschnitte, die die NFL für sehenswert hält. Das ist ungefähr das, was Destillation tut.
Die drei Operationen im Detail
DeepSeek: 150.000 Reasoning-Dialoge
DeepSeeks Operation zielte auf Claudes Reasoning-Fähigkeiten ab. Über 150.000 Austausche generierten sie Chain-of-Thought-Trainingsdaten im grossen Stil. Ihre Prompts baten Claude, die interne Logik hinter einer abgeschlossenen Antwort vorzustellen und Schritt für Schritt aufzuschreiben -- um effektiv die Reasoning-Traces zu erzeugen, die zum Training eines Konkurrenzmodells nötig sind.
Eine ihrer aufschlussreichsten Techniken hatte nichts mit militärischen Anwendungen zu tun: Sie nutzten Claude, um zensursichere Alternativen zu politisch sensiblen Anfragen über Dissidenten, Parteiführer und Autoritarismus zu generieren. Trainingsdaten, die darauf ausgelegt sind, DeepSeeks eigenen Modellen beizubringen, Gespräche von Themen wegzulenken, die die chinesische Regierung nicht diskutiert sehen will.
Moonshot: 3,4 Millionen Austausche
Moonshot führte 3,4 Millionen Austausche über Hunderte gefälschter Accounts durch und zielte auf agentisches Reasoning, Tool-Nutzung, Computer-Nutzung, Agent-Entwicklung und Computer Vision. In einer späteren Phase wechselten sie zu einem chirurgischeren Ansatz und versuchten, Claudes Reasoning-Traces direkt zu extrahieren und zu rekonstruieren. Das Ergebnis ist Kimi.
Minimax: 13 Millionen Coding-Austausche
Minimax, die grösste der drei Operationen, führte über 13 Millionen Austausche durch, die spezifisch auf agentisches Coding und Tool-Orchestrierung ausgerichtet waren.
Warum Benchmark-Ergebnisse täuschen
Das Brittleness-Problem
Destillierte Modelle schneiden bei Benchmarks gut ab -- oft sogar vergleichbar mit dem Original. Warum? Weil Benchmarks genau die Art von Aufgaben testen, für die der Destillierer optimiert hat.
Ein Enterprise-Käufer, der eine Standard-Evaluierungssuite durchführt, könnte schliessen, die Modelle seien ungefähr gleichwertig. Er würde sich irren.
Das destillierte Modell hat gelernt, Ausgaben zu produzieren, die wie Claudes Ausgaben bei Coding-Aufgaben aussehen. Es hat nicht die zugrundeliegende Repräsentationsstruktur gelernt, die Claude erlaubt:
- Über verschiedene Aufgabentypen hinweg zu generalisieren
- Sich von unerwarteten Fehlern zu erholen
- Werkzeuge in Kombinationen zu nutzen, auf die es nicht spezifisch trainiert wurde
- Kohärentes Reasoning über ausgedehnte autonome Workflows aufrechtzürhalten
Wo der Unterschied sichtbar wird
Bei kurzen, klar definierten Aufgaben (Chatbot-Antworten, einzelne Übersetzungen, isolierte Code-Snippets) mag ein destilliertes Modell 90 Prozent so gut sein wie das Frontier-Modell -- für 15 Prozent der Kosten. Diesen Trade-off würde man jederzeit eingehen.
Bei ausgedehnter autonomer Arbeit (ein wöchenlanger Coding-Sprint über sechs Repositories, bei dem das Modell organisatorischen Kontext verstehen, Arbeit korrekt zuordnen, sich von unbekannten Fehlern erholen und Werkzeuge in unvorhergesehenen Kombinationen nutzen muss) ist das destillierte Modell vielleicht nur 40 Prozent so effektiv.
Der Leistungsschatten zwischen Frontier- und destillierten Modellen bei kurzen Aufgaben ist relativ schmal. Der Leistungsschatten bei ausgedehnter agentischer Arbeit ist gross -- und wird grösser. Und kein Benchmark erfasst das heute zuverlässig.
Ein praktisches Beispiel: Kimi K2
Kimi K2 (aufgebaut auf Moonshots extrahierten Daten) glänzt bei PowerPoint-Generierung: schönes Design, saubere Ausführung, relativ schnelle Iteration. Aber bei nachhaltiger agentischer Arbeit -- wo ein KI-Modell autonom Hindernisse navigieren, recherchieren, einem Styleguide folgen und seinen Ansatz über einen mehrstündigen Workflow anpassen muss -- bricht die Leistung ein.
Der Unterschied zeigt sich als eingeschränkte Fähigkeit, um Hindernisse herum zu arbeiten und ein längerfristiges Ziel zuverlässig und autonom zu verfolgen. Ein Frontier-Modell trifft auf einen unerwarteten Fehler mitten in einer komplexen Coding-Aufgabe und weiss, wie es umleiten kann. Es probiert eine andere Bibliothek, strukturiert seinen Ansatz um, fragt nach Klärung bei echten Mehrdeutigkeiten. Ein engeres Modell trifft auf denselben Fehler und scheitert, loopt oder produziert einen technisch validen, aber strategisch falschen Workaround.
Was das für dich bedeutet
Bei der Werkzeug-Auswahl
- Für einfache Chat-Aufgaben: Destillierte Modelle können völlig ausreichen und deutlich günstiger sein
- Für agentische Workflows und autonome Arbeit: Frontier-Modelle sind derzeit alternativlos
- Für kritische Geschäftsentscheidungen: Verstehe, ob das Modell, das du nutzt, ein Original oder ein Destillat ist
Bei der Bewertung von Anbietern
Standard-Benchmarks reichen nicht. Frage nach:
- Wie verhalt sich das Modell bei mehrstündigen autonomen Aufgaben?
- Wie geht es mit unerwarteten Fehlern und Werkzeugkombinationen um, die nicht im Training vorkamen?
- Ist das Modell ein Frontier-Modell oder basiert es auf extrahierten Fähigkeiten eines anderen Modells?
Bei der Enterprise-Strategie
Das grösste unterschätzte Risiko in Enterprise-KI ist heute der Performance-Schatten auf agentischer Arbeit. Evaluierungssuiten, die nachhaltige autonome Generalisierung messen würden, existieren noch kaum. Das bedeutet: Du brauchst eigene Tests, die über Standard-Benchmarks hinausgehen.
Die breitere Perspektive
Es ist kein reines China-Problem
Die Versuchung, Destillation als geopolitisches Problem zu rahmen, ist gross. Und die Realität ist: Die Geopolitik im Pazifik ist real. Aber der Anreiz zur Destillation würde existieren, selbst wenn China und die USA enge Verbündete wären. Er existiert, weil die Kosten für die Erzeugung von Intelligenz astronomisch höher sind als die Kosten für das Kopieren dieser Intelligenz. Das ist reine Informationsökonomie.
Was die Labs dagegen tun
Anthropic konnte die Kampagnen durch Zahlungsmethoden und Request-Metadaten zu spezifischen Forschern zurückverfolgen. Die technischen Gegenmassnahmen umfassen:
- Erkennung automatisierter Konversationsmuster
- Geografische und Account-basierte Zugangskontrollen
- Modell-Fingerprinting zur Erkennung von Destillaten
- Watermarking von Modell-Ausgaben
Aber wie bei jeder Sicherheitsmassnahme: Es ist ein Katz-und-Maus-Spiel, das nie vollständig gewonnen werden kann.
Fazit
KI-Destillation ist nicht nur ein Sicherheitsthema für die Frontier-Labore. Es ist ein praktisches Thema für jeden, der KI-Werkzeuge einsetzt. Die wichtigsten Erkenntnisse:
- Nicht alle Modelle sind gleich: Benchmark-Ergebnisse können täuschen, besonders bei agentischen Aufgaben
- Der Leistungsschatten wächst: Je autonomer und länger die Aufgabe, desto grösser der Unterschied zwischen Original und Destillat
- Frontier-Modelle haben Repräsentationstiefe: Sie können improvisieren, generalisieren und sich erholen -- Fähigkeiten, die bei der Destillation verloren gehen
- Eigene Evaluierung ist unverzichtbar: Standard-Benchmarks erfassen die relevantesten Leistungsunterschiede nicht
- Der Anreiz zur Destillation verschwindet nicht: Es ist ein strukturelles Problem der Informationsökonomie, kein einmaliger Vorfall
Für die praktische Nutzung bedeutet das: Verstehe, welches Modell du nutzt, wie es entstanden ist und wo seine Grenzen liegen. Die Qualität deiner KI-Werkzeuge bestimmt zunehmend die Qualität deiner Arbeit -- und der Unterschied zwischen Frontier und Destillat wird mit jeder Generation agentischer werden.