Frontier Operations: KI-Kompetenz als dynamische Praxis
Einleitung
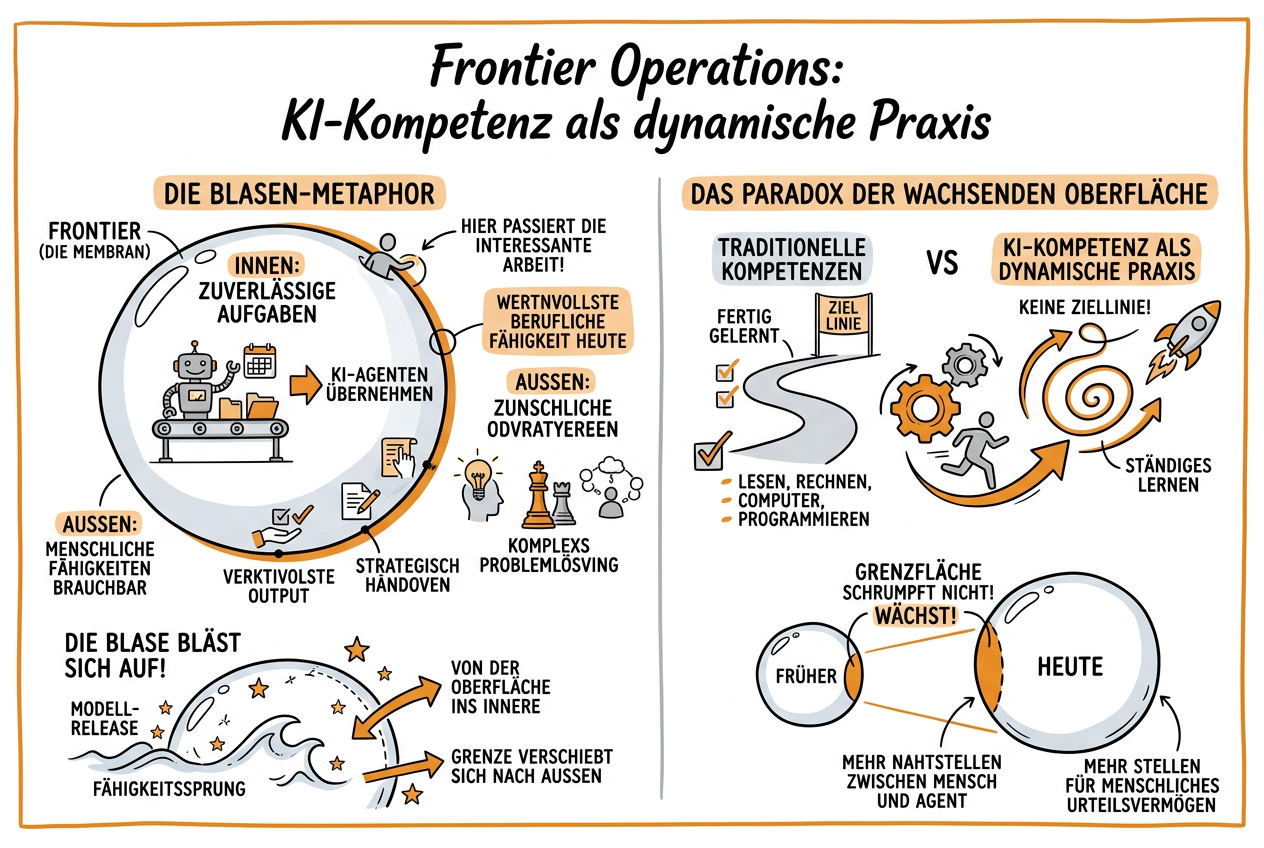
Jede Arbeitsfähigkeit in der Geschichte hatte bisher eine Ziellinie -- einen Punkt, an dem man fertig gelernt hatte. KI nicht.
Stell dir eine Blase vor. Die Luft innen ist alles, was KI-Agenten heute zuverlässig erledigen können. Die Luft aussen ist alles, was noch einen Menschen braucht. Die Oberfläche dieser Blase -- diese dünne, gekrümmte Membran -- das ist, wo die interessante Arbeit gerade passiert.
Dort entscheidest du, was du delegierst und was du behältst. Dort verifizierst du Agent-Output, greifst ein wenn nötig, strukturierst die Übergaben. An dieser Oberfläche gut zu arbeiten ist die wertvollste professionelle Fähigkeit in der Wirtschaft heute.
Aber die Blase bläst sich auf. Mit jedem Modell-Release, jedem Fähigkeitssprung wandern Aufgaben von der Oberfläche ins Innere, wo Agenten sie übernehmen. Und die Grenze verschiebt sich weiter nach aussen.
Das Paradox der wachsenden Oberfläche
Wenn eine Blase expandiert, wächst ihre Oberfläche. Die Frontier schrumpft nicht, wenn KI fähiger wird -- sie wächst. Es gibt mehr Grenzfläche, an der operiert werden muss. Mehr Stellen für menschliches Urteilsvermögen, nicht weniger. Mehr Nahtstellen zwischen Mensch und Agent, nicht weniger.
Das unterscheidet diese Fähigkeit fundamental von allem, was je gelehrt wurde. Lesen, Rechnen, Computer-Kompetenz, Programmieren -- alles war ein Ziel. Du hast es erreicht, du hast es, du bist fertig. Das Ziel bewegt sich nicht.
Die Fähigkeit, an der Oberfläche dieser Blase zu arbeiten, hat kein festes Ziel, weil die Oberfläche sich ständig nach aussen ausdehnt. Du kannst es nicht einmal lernen. Du kannst lernen, darauf zu bleiben, dich mit der Expansion zu bewegen, dein Gleichgewicht zu halten, während sich die Krümmung unter dir verschiebt.
Die KI-Kompetenzleiter: Wo stehst du?
Level 1: Fragen stellen
ChatGPT ist im Grunde eine schlaue Suchmaschine für dich. Es antwortet, du konsumierst.
Dein nächster Schritt: Höre auf, deine Fragen zu stellen, und bitte die KI, dir Fragen zu stellen. Statt den perfekten Prompt zu formulieren, dreh es um. Lass dich interviewen. Dieser eine Wechsel -- KI vom Antwortautomaten zum Denkpartner -- verändert alles.
Level 2: Echte Arbeit machen
Du lässt KI Emails schreiben, Tabellen zusammenfassen, vielleicht etwas bauen. Du siehst echte Ergebnisse und hast starke Meinungen entwickelt: "Es ist inkonsistent." "Ich kann dem nicht vertrauen." "Es halluziniert zu viel."
Das ist die Falle. Diese Beobachtungen sind nicht falsch. KI ist inkonsistent. Sie halluziniert. Das Problem ist, dass du dort stehen geblieben bist. Du hast Beobachtungen in Urteile verwandelt. Und wenn du entschieden hast, was KI kann und was nicht, hörst du auf zu erkunden.
Level 3: Erkunden und Wundern
Der Wechsel von Level 2 zu Level 3 ist ein einziges Wort: Wonder (Neugier/Staunen).
In Level 2 gibt dir KI ein schlechtes Ergebnis und dein Instinkt ist zu urteilen: "Das hat nicht funktioniert. KI kann das nicht." In Level 3 wird dein Instinkt: "Das hat nicht funktioniert. Ich frage mich, ob ich das Problem falsch gerahmt habe. Ob es funktionieren würde, wenn ich es in Teile zerlege. Ob ich zu viel Information gegeben habe."
Wenn du in Level 3 gleitest, realisierst du, dass die Art, wie du mit KI in einem Bereich gearbeitet hast, überall anwendbar sein könnte. KI könnte dir helfen, einen Raum umzugestalten, 12 Emails zu priorisieren oder herauszufinden, was mit deinem Ellbogen los ist.
Die Zeitinvestition: Der volle Wechsel zu Level 3 braucht etwa ein Jahr an Praxis. Aber: Im ersten Monat wirst du die Leute hinter dir lassen, die immer noch sagen "Ich habs probiert, es ist so nervig." Was du aufbaust, ist Intuition -- eine mentale Karte davon, wie diese Systeme funktionieren. Intuition kommt nicht vom Lesen. Sie kommt vom Tun.
Level 4 & 5: Systeme designen und vertrauen
Ab Level 4 designst du Systeme um die Arbeit herum, statt selbst in der Arbeit zu sein. Ab Level 5 designst du vollautonom arbeitende Systeme. Das ist der Horizont -- aber Level 3 führt natürlich zu Level 4.
Die fünf Frontier-Operations-Fähigkeiten
1. Boundary Sensing (Grenzwahrnehmung)
Die Fähigkeit, eine aktülle, genaue operative Intuition darüber zu halten, wo die Mensch-Agent-Grenze für eine bestimmte Domäne liegt.
Das Update-Problem: Opus 4.5 konnte Informationen tief in einem langen Dokument nicht zuverlässig abrufen. Drei Monate später erreicht Opus 4.6 93% bei Retrieval auf 256.000 Tokens. Wer seine Grenzwahrnehmung am November-Modell kalibriert hat und nicht aktualisiert, vertraut dem Februar-Modell entweder zu viel oder nutzt es zu wenig.
Praxis-Beispiel Produktmanager: Ein Agent erstellt eine glaubwürdige Wettbewerbsanalyse, verpasst aber die politischen Dynamiken zwischen zwei Führungskräften. Gutes Boundary Sensing: Marktsizing und Feature-Vergleich an den Agenten, Stakeholder-Dynamiken selbst bearbeiten.
Praxis-Beispiel Marketing-Leiterin: Ein Agent produziert einen soliden Erstentwurf für Kampagnen-Copy. Aber die Markenstimme driftet subtil nach der dritten Version. Lösung: Agent für Ideation und ersten Entwurf nutzen, Stimme selbst editieren, nicht über Version 2 hinaus iterieren lassen.
2. Seam Design (Naht-Design)
Die Fähigkeit, Arbeit so zu strukturieren, dass Übergänge zwischen menschlichen und Agent-Phasen sauber, verifizierbar und wiederherstellbar sind.
Die zentrale Frage: Wenn ich dieses Projekt in sieben Phasen zerlege -- welche drei sind voll agent-ausführbar? Welche zwei brauchen Human-in-the-Loop? Welche zwei sind irreducibel menschlich? Welche Artefakte werden zwischen den Phasen übergeben? Was muss ich bei jeder Übergabe sehen, um zu wissen, dass alles auf Kurs ist?
Praxis-Beispiel Beratung: Recherche (agent-geführt mit menschlich definiertem Scope), Synthese (mensch-geführt mit agent-generierten Framework-Entwürfen), Kundenpräsentation (mensch-geführt mit agent-generierten Slide-Entwürfen). Die Naht zwischen Recherche und Synthese ist ein strukturiertes Deliverable: eine Faktenbasis mit Quellzitaten, die der Mensch in wenigen Minuten stichprobenartig prüfen kann.
3. Failure Model Maintenance (Fehlermodell-Pflege)
Die Fähigkeit, ein genaues, aktülles mentales Modell darüber zu pflegen, wie Agenten versagen. Nicht dass sie versagen, sondern die spezifische Textur und Form des Versagens auf dem aktüllen Fähigkeitsniveau.
Früher vs. heute: Frühe Sprachmodelle versagten offensichtlich -- wirrer Text, falsche Fakten, inkohärent. Aktülle Frontier-Modelle versagen subtil: korrekt klingende Analyse auf einer missverstandenen Prämisse. Plausibler Code, der den Happy Path abdeckt, aber bei Edge Cases bricht. Forschungszusammenfassungen, die zu 98% korrekt sind, während die restlichen 2% zuversichtlich fabriziert sind.
Praxis-Beispiel Unternehmensrecht: Ein Agent, der Verträge prüft, findet Boilerplate-Probleme, verpasst aber nicht-standardmässige Kündigungsklauseln und die Wechselwirkung zwischen einer Haftungsbegrenzung und einem Carve-out in den Anhängen. Fehlermodell: Boilerplate-Scan vertrauen, Querverweise zwischen Haftungsbestimmungen und Anhängen manüll prüfen.
Praxis-Beispiel Data Scientist: Ein Agent, der Python für Datenanalyse generiert, behandelt Pandas-Transformationen zuverlässig, produziert aber plausibel klingenden Unsinn bei chaotischen Edge Cases. Fehlermodell: Datenbereinigungsschritte und Spalten-Semantik verifizieren, dann der nachgelagerten Analyse vertrauen.
4. Capability Forecasting (Fähigkeitsprognose)
Die Fähigkeit, vernünftige kurzfristige Vorhersagen darüber zu treffen, wohin sich die Blasen-Grenze als nächstes bewegt, und Lernen und Workflow-Entwicklung entsprechend zu investieren.
Die Surfer-Analogie: Ein guter Surfer sagt nicht voraus, wie die nächste Welle genau aussehen wird. Aber er liest das Meer, versteht, wie der Boden die Wellen an diesem bestimmten Break formt, und positioniert sich dort, wo die nächste reitbare Welle am wahrscheinlichsten entsteht.
Praxis: Wer Anfang 2025 die Trajektorie von Coding-Agenten beobachtete, konnte erkennen, dass sich Investitionen in Code-Review und Spezifikations-Skills lohnen würden -- statt nur in rohes Coding. Ein UX-Researcher, der sieht, wie Agenten bei Survey-Design besser werden, investiert in interpretative Synthese: die Fähigkeit, kodierte Daten in Produkt-Insights zu verwandeln.
5. Leverage Calibration (Hebel-Kalibrierung)
Die Fähigkeit, hochwertige Entscheidungen darüber zu treffen, wo menschliche Aufmerksamkeit -- jetzt die knappste Ressource -- eingesetzt wird.
Die Mathematik: 100 Streams von Agent-Output und 8 Stunden am Tag. Du kannst nicht alles auf der gleichen Tiefe prüfen. Die Fähigkeit ist, deine eigene Aufmerksamkeit in Echtzeit zu triagieren.
Praxis-Beispiel Engineering Manager: Hierarchische Aufmerksamkeitsallokation:
- Routine-Tier: Agent-generierter Code fliesst durch automatisierte Test-Suites
- Mittlerer Tier: Billing- und Daten-Pipeline-Code wird für Human Code Review geflaggt
- Tiefer Tier: Architektur-Entscheidungen und systemübergreifende Änderungen bekommen tiefes menschliches Engagement
Die Schwellenwerte werden monatlich rekalibriert, weil die Agenten im Routine-Tier besser werden.
Team-Strukturen der Zukunft
Team of One
Eine einzelne Person mit starken Frontier-Operations-Skills, die mehrere Agent-Workflows über eine Domäne leitet. Output wie ein 5-10-Personen-Team -- nicht durch härtere Arbeit, sondern durch kontinuierliches Delegieren und intelligentes Verifizieren.
Team of Five (Pod)
Eine Person mit tiefen Frontier-Operations-Skills, einige mit sich entwickelnden Skills, einige Spezialisten mit irreplaceable Domänenexpertise. Der Frontier Operator setzt die Nahtstellen, pflegt die Fehlermodelle, kalibriert die Aufmerksamkeitsallokation. Der Pod shipped wie ein 20-Personen-Team.
Wie du die Fähigkeiten entwickelst
Als Individual Contributor
- Tracke deine Überraschungen: Wo überraschen dich Agenten? Die Überraschung ist das Signal. Wenn dein Agent dich kürzlich nicht überrascht hat, operierst du nicht an der Grenze.
- Sammle bewusst: Logge, wo deine Grenzwahrnehmung falsch war, und baue deine professionelle Intuition auf
- Gib deinem Agenten einen Job, der dich überrascht -- ob er scheitert oder teils gelingt
Als Führungskraft
- Schaue auf die Aufmerksamkeitsallokation: Prüft dein Team alles auf der gleichen Tiefe? Gibt es einen Engpass, der sich als Sorgfalt tarnt?
- Schaffe explizite Rollen: Die Fähigkeit entwickelt sich nicht, wenn sie undifferenzierter Teil von jemand anderem Job ist
- Messe Kalibrierung, nicht Wissen: Die richtige Bewertung ist nicht "Kannst du einen guten Prompt schreiben?" sondern "Kannst du bei einer Aufgabe und einem Agenten auf Fähigkeitslevel X genau vorhersagen, wo der Agent Erfolg hat, wo er scheitert und wie du deine Arbeit entsprechend strukturierst?"
Maximiere Feedback-Dichte
Die Geschwindigkeit der Skill-Entwicklung ist eine Funktion davon, wie viele Zyklen eine Person mit KI pro Zeiteinheit durchläuft -- nicht eine lineare Funktion von Trainingsstunden.
40 Stunden KI-Kurs offsite, dann zurück zur Arbeit mit leichtem ChatGPT-Gebrauch: null Kalibrierungszyklen. 10 echte Aufgaben pro Tag an einen Agenten delegieren und den Output bewerten: 100 Zyklen in 10 Tagen.
Fazit
Frontier Operations ist die erste Arbeitsfähigkeit in der Geschichte, die auf einem ungefähr vierteljährlichen Zyklus abläuft. Das bedeutet: Alles, was wir über das Lehren von Arbeitsfähigkeiten wissen, funktioniert hier nicht besonders gut.
Die fünf Fähigkeiten in Kurzform:
- Boundary Sensing: Wo liegt die Grenze aktüll? Kalibrierung halten.
- Seam Design: Übergänge zwischen Mensch und Agent sauber strukturieren.
- Failure Model Maintenance: Wie genau versagen Agenten bei welchen Aufgaben?
- Capability Forecasting: Wohin bewegt sich die Grenze als nächstes?
- Leverage Calibration: Wo erzeugt menschliche Aufmerksamkeit den meisten Wert?
Diese sind keine Checkliste. Sie sind fünf simultane, integrierte, kontinuierliche Operationen -- wie Autofahren Lenkung, Geschwindigkeitsmanagement, Routenbewusstsein und Gefahrenwahrnehmung gleichzeitig einschliesst.
Der Vorsprung kompoundiert: Wer diese Fähigkeiten sechs Monate früher entwickelt, hat nicht nur einen Sechsmonatsvorsprung, sondern sechs Monate aktualisierter Kalibrierung, die der Nachzügler nicht hat. Und weil die Fähigkeiten sich beschleunigen, wird der Abstand mit jedem Modell-Release grösser.