Context Engineering: Die Kunst der KI-Steuerung
Lektion 1: Was ist Context Engineering?
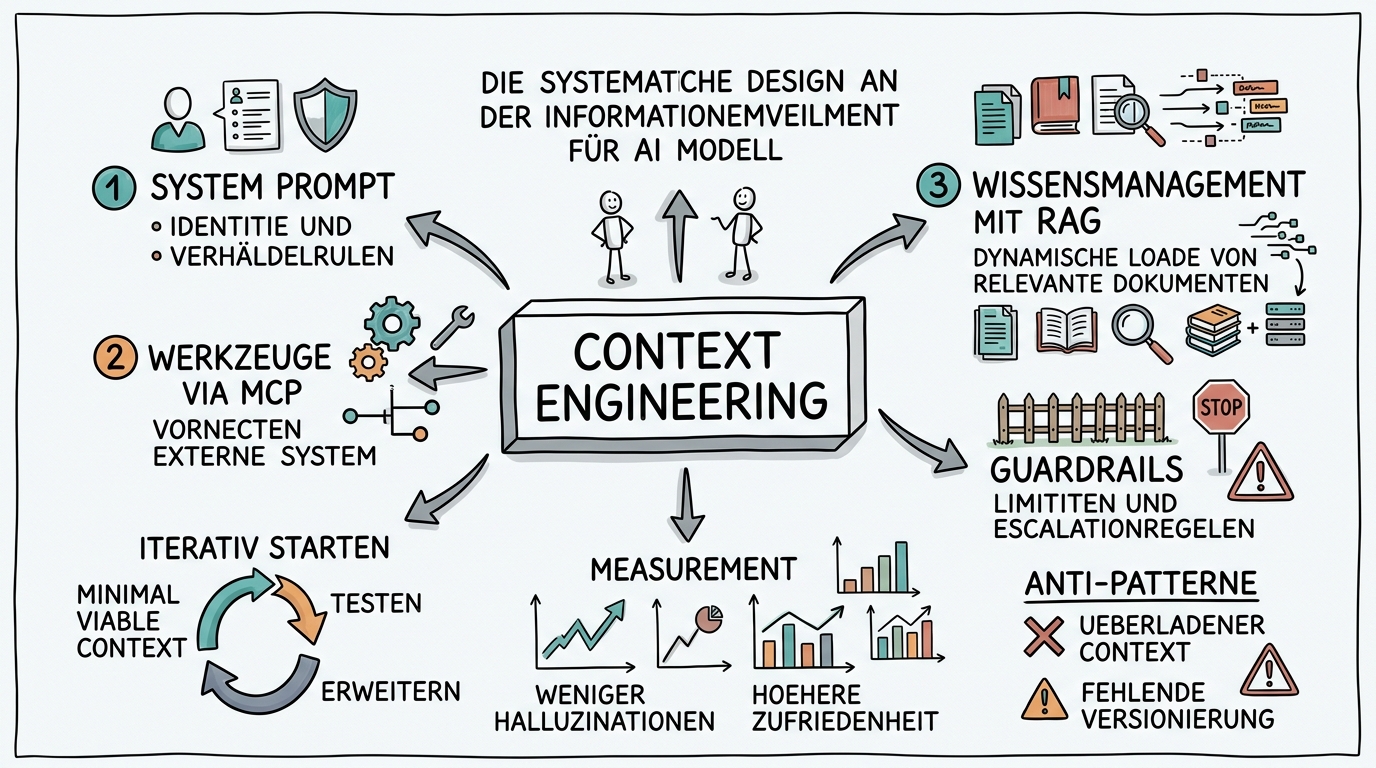
Der Begriff Context Engineering beschreibt einen fundamentalen Wandel in der Art, wie wir mit KI-Systemen arbeiten. Während Prompting sich auf die einzelne Anfrage konzentriert, geht Context Engineering weit darüber hinaus: Es gestaltet das gesamte Informationsumfeld, in dem ein KI-Modell operiert. Stellen Sie sich vor, Sie würden nicht nur eine Frage an einen Experten richten, sondern sein gesamtes Büro einrichten — mit den richtigen Nachschlagewerken, Werkzeugen, Vorlagen und Hintergrundinformationen.
In der Praxis bedeutet das: Sie definieren nicht nur, was das Modell tun soll, sondern auch, was es weiss, welche Werkzeuge es nutzen kann, wie es sich verhalten soll und welche Einschränkungen gelten. Ein gut konstruierter Context ist wie ein präzise eingerichteter Arbeitsplatz — er ermöglicht dem Modell, konsistent hochwertige Ergebnisse zu liefern, ohne dass jede einzelne Anfrage bis ins Detail spezifiziert werden muss.
Der Unterschied zum klassischen Prompting ist erheblich. Ein Prompt ist eine einzelne Anweisung: "Schreibe mir eine E-Mail an den Kunden." Context Engineering hingegen umfasst das gesamte System: Wer ist der Kunde? Welchen Tonfall verwenden wir? Welche früheren Interaktionen gab es? Welche Unternehmensrichtlinien gelten? Welche Datenquellen stehen zur Verfügung? All diese Informationen werden systematisch aufbereitet und dem Modell zur Verfügung gestellt.
Für Unternehmen wird Context Engineering 2026 zur Kernkompetenz. Die Qualität der KI-Ausgaben hängt nicht mehr primär vom Modell ab — die führenden Modelle sind alle leistungsfähig genug. Der entscheidende Unterschied liegt darin, wie gut der Context gestaltet ist. Wer Context Engineering beherrscht, holt aus jedem Modell bessere Ergebnisse heraus als jemand, der nur einzelne Prompts optimiert.
Lektion 2: Die vier Sauelen des Context Engineering
Context Engineering ruht auf vier Sauelen, die zusammen ein robustes Fundament bilden. Die erste Saule ist der System Prompt — die grundlegende Identität und Verhaltensanweisung für das Modell. Ein guter System Prompt definiert nicht nur, was das Modell tun soll, sondern auch, wie es denken soll. Er legt Persönlichkeit, Fachwissen, Grenzen und Priorisierungen fest. Anders als bei einem einfachen Prompt geht es hier um eine dauerhafte Konfiguration, die über viele Interaktionen hinweg konsistent bleibt.
Die zweite Saule bilden die verfügbaren Werkzeuge und Datenquellen. Moderne KI-Systeme können über Schnittstellen wie das Model Context Protocol auf externe Systeme zugreifen — Datenbanken, APIs, Dateisysteme, Kalender und mehr. Die Kunst liegt darin, genau die richtigen Werkzeuge bereitzustellen: zu wenige schränken die Handlungsfähigkeit ein, zu viele verwirren das Modell und führen zu Fehlentscheidungen. Ein erfahrener Context Engineer wählt die Werkzeuge so aus, dass sie die häufigsten Aufgaben abdecken, ohne das Modell zu überfordern.
Die dritte Saule ist das Wissensmanagement. Welche Dokumente, Fakten und Hintergrundinformationen stehen dem Modell zur Verfügung? Retrieval-Augmented Generation, also das dynamische Nachladen relevanter Informationen, ist hier das Mittel der Wahl. Aber die Qualität des Retrievals hängt massgeblich davon ab, wie die Wissensbasis strukturiert ist. Schlecht aufbereitete Dokumente führen zu schlechten Antworten, unabhängig davon, wie gut das Modell ist.
Die vierte Saule schliesslich sind die Leitplanken und Einschränkungen. Jedes KI-System braucht klare Grenzen: Was darf es nicht tun? Welche Themen soll es vermeiden? Wie soll es mit Unsicherheit umgehen? Diese Guardrails sind besonders in Unternehmensumgebungen entscheidend, wo ein unkontrolliertes KI-System erheblichen Schaden anrichten kann. Gute Leitplanken sind spezifisch genug, um Risiken zu minimieren, aber flexibel genug, um die Nützlichkeit des Systems nicht übermassig einzuschränken.
Lektion 3: System Prompts professionell gestalten
Ein professioneller System Prompt ist weit mehr als eine Handvoll Anweisungen. Er ist ein sorgfältig strukturiertes Dokument, das oft mehrere tausend Wörter umfasst und in klar definierten Sektionen organisiert ist. Die beste Praxis beginnt mit einer Rollendefinition: Wer ist dieses KI-System? Ein Kundenberater für ein Softwareunternehmen? Ein medizinischer Informationsassistent? Ein interner Wissensmanager? Diese Rolle muss so präzise beschrieben werden, dass das Modell in jeder Situation konsistent reagieren kann.
Nach der Rollendefinition folgen die Verhaltensregeln. Hier wird festgelegt, wie das Modell kommunizieren soll — formell oder informell, ausführlich oder knapp, proaktiv oder reaktiv. Ein Beispiel aus der Praxis: Ein Versicherungsunternehmen konfiguriert seinen KI-Assistenten so, dass er bei Schadensmeldungen immer zunächst Empathie zeigt, dann systematisch die relevanten Informationen abfragt und schliesslich den nächsten Schritt erklärt. Diese Verhaltenskette ist im System Prompt codiert und sorgt dafür, dass jeder Kunde die gleiche hochwertige Erfahrung macht.
Besonders wichtig sind die Eskalationsregeln. Ein gut gestalteter System Prompt definiert klar, wann das Modell an einen menschlichen Mitarbeiter übergeben soll. Typische Eskalationsgründe sind: rechtliche Fragen, Beschwerden ab einer bestimmten Schwere, technische Probleme ausserhalb des Kompetenzbereichs oder emotionale Situationen, die menschliches Eingreifen erfordern. Ohne diese Regeln neigen KI-Systeme dazu, auch in Situationen zu antworten, in denen sie besser schweigen sollten.
Ein oft unterschätzter Aspekt ist die Formatierungsanweisung. Soll das Modell mit Markdown antworten? In welcher Länge? Mit oder ohne Aufzählungen? Diese scheinbar trivialen Details machen in der Praxis einen enormen Unterschied, besonders wenn die Ausgaben in bestehende Systeme integriert werden. Ein System Prompt für einen Chatbot, der in einer mobilen App läuft, braucht andere Formatierungsregeln als einer, der Berichte für ein Management-Dashboard generiert.
Lektion 4: Retrieval-Augmented Generation strategisch einsetzen
Retrieval-Augmented Generation — kurz RAG — ist das Rückgrat des modernen Context Engineering. Die Grundidee ist elegant: Statt alle Informationen direkt in den Prompt zu packen, werden relevante Dokumente dynamisch nachgeladen, wenn sie gebraucht werden. Das löst eines der grössten Probleme von KI-Systemen: begrenztes Kontextfenster bei gleichzeitig riesigen Wissensbeständen.
In der Unternehmenspraxis funktioniert RAG so: Ein Mitarbeiter stellt eine Frage an den KI-Assistenten. Bevor das Modell antwortet, durchsucht ein Retrieval-System die interne Wissensbasis — Handbücher, Prozessdokumentationen, frühere Tickets, Verträge — und liefert die relevantesten Abschnitte als zusätzlichen Context. Das Modell kann dann auf Basis dieser spezifischen, aktüllen Informationen antworten, statt auf sein allgemeines Trainingswissen zurückzugreifen.
Die Qualität eines RAG-Systems steht und fällt mit der Aufbereitung der Wissensbasis. Einfach alle Dokumente in eine Vektordatenbank zu werfen, reicht bei weitem nicht aus. Professionelles Context Engineering erfordert eine durchdachte Chunking-Strategie: Wie werden Dokumente in sinnvolle Abschnitte zerlegt? Zu kleine Chunks verlieren den Zusammenhang, zu grosse verschwenden wertvolle Kontextfenster-Kapazität. Die besten Ergebnisse erzielen semantische Chunking-Verfahren, die natürliche Sinnabschnitte erkennen und bewahren.
Ein fortgeschrittenes Konzept ist Agentic RAG, bei dem das KI-Modell selbst entscheidet, wann und wie es nach Informationen sucht. Statt bei jeder Anfrage automatisch eine Suche auszulösen, bewertet ein Agentic RAG-System zunächst, ob zusätzliche Informationen überhaupt nötig sind. Wenn ja, formuliert es eigenständig Suchanfragen, bewertet die Ergebnisse kritisch und fordert bei Bedarf weitere Informationen an. Dieses Vorgehen ist effizienter und liefert präzisere Ergebnisse als einfaches RAG.
Lektion 5: Werkzeugintegration mit dem Model Context Protocol
Das Model Context Protocol hat sich 2026 als universeller Standard für die Anbindung externer Werkzeuge an KI-Systeme etabliert. Ähnlich wie USB-C eine einheitliche Schnittstelle für Hardware bietet, standardisiert MCP die Kommunikation zwischen KI-Modellen und externen Diensten. Für Context Engineers ist MCP ein Game-Changer, denn es ermöglicht die systematische Erweiterung der Fähigkeiten eines KI-Systems, ohne dass für jede Integration individüller Code geschrieben werden muss.
Die praktische Bedeutung zeigt sich an einem Beispiel: Ein Beratungsunternehmen möchte seinen KI-Assistenten mit dem CRM-System, dem Kalender und der Wissensdatenbank verbinden. Ohne MCP müsste für jedes System eine separate Integration entwickelt werden, mit unterschiedlichen Authentifizierungsmethoden, Datenformaten und Fehlerbehandlungen. Mit MCP stellt jedes System einen standardisierten Server bereit, und der KI-Assistent kann über einen einheitlichen Client auf alle Systeme zugreifen.
Für das Context Engineering bedeutet MCP eine neue Dimension der Gestaltungsmöglichkeiten. Der Context Engineer definiert nicht nur, was das Modell weiss und wie es sich verhält, sondern auch, welche Aktionen es in der realen Welt ausführen kann. Ein gut konfiguriertes MCP-Setup kann dem Modell ermöglichen, Termine zu vereinbaren, E-Mails zu versenden, Datenbankabfragen durchzuführen und Berichte zu erstellen — alles im Rahmen klar definierter Berechtigungen und Sicherheitsrichtlinien.
Die Roadmap für MCP in 2026 konzentriert sich auf Enterprise-Fähigkeiten: standardisierte Audit-Trails, damit jede Aktion nachvollziehbar ist, sichere Authentifizierung über Single Sign-On, und skalierbare Architekturen für den Cloud-Betrieb. Besonders spannend ist die geplante Agent-to-Agent-Kommunikation, die es verschiedenen KI-Systemen ermöglicht, über MCP direkt miteinander zu interagieren und komplexe Aufgaben gemeinsam zu lösen.
Lektion 6: Context Engineering in der Unternehmenspraxis
Die Einführung von Context Engineering in einem Unternehmen beginnt typischerweise mit der Identifikation der wichtigsten Anwendungsfälle. Ein mittelständisches Unternehmen mit 200 Mitarbeitern würde etwa mit dem Kundenservice beginnen, wo die grösste Hebelwirkung zu erwarten ist. Der Context Engineer analysiert zunächst die bestehenden Prozesse: Welche Fragen stellen Kunden am häufigsten? Welche Informationen benötigen die Mitarbeiter, um diese Fragen zu beantworten? Wo entstehen Verzögerungen oder Fehler?
Auf Basis dieser Analyse wird der Context Schicht für Schicht aufgebaut. Zürst der System Prompt, der den KI-Assistenten als kompetenten Kundenberater mit den spezifischen Produktkenntnissen des Unternehmens konfiguriert. Dann die RAG-Anbindung an die Produktdatenbank, die FAQ-Sammlung und die Wissensbasis mit Lösungen für bekannte Probleme. Schliesslich die MCP-Integration mit dem Ticketsystem, damit der Assistent Vorgänge anlegen, aktualisieren und eskalieren kann.
Ein häufiger Fehler in der Praxis ist der Versuch, alles auf einmal zu implementieren. Erfahrene Context Engineers arbeiten iterativ: Sie starten mit einem Minimal Viable Context, testen ihn mit echten Nutzern, sammeln Feedback und erweitern den Context schrittweise. Dieser Ansatz hat sich bewährt, weil er früh zeigt, welche Teile des Contexts funktionieren und wo Nachbesserungsbedarf besteht. Ein Unternehmen, das mit einem perfekten System starten will, verzettelt sich oft in der Planung und kommt nie zur Umsetzung.
Die Messung des Erfolgs ist ein weiterer kritischer Aspekt. Context Engineering ist dann erfolgreich, wenn die Qualität der KI-Ausgaben messbar steigt — weniger Halluzinationen, höhere Kundenzufriedenheit, schnellere Bearbeitungszeiten. Moderne Monitoring-Systeme können diese Metriken automatisch erfassen und Trends sichtbar machen. So entsteht ein kontinuierlicher Verbesserungskreislauf, bei dem der Context auf Basis realer Daten optimiert wird.
Lektion 7: Fortgeschrittene Techniken und Anti-Patterns
Context Engineering bietet eine Reihe fortgeschrittener Techniken, die über die Grundlagen hinausgehen. Eine davon ist das Chain-of-Thought Scaffolding: Im System Prompt wird nicht nur das gewünschte Ergebnis beschrieben, sondern auch der Denkprozess, den das Modell durchlaufen soll. Für komplexe Analysaufgaben kann das bedeuten, dass der Context explizit vorgibt: Erst die Fakten sammeln, dann Widersprüche identifizieren, dann Hypothesen bilden, dann die stärkste Hypothese auswählen und begründen.
Eine weitere Technik ist die dynamische Context-Anpassung. Statt einen statischen Context für alle Situationen zu verwenden, passt das System den Context je nach Gesprächsverlauf an. Wenn ein Kunde im Chat zunächst eine allgemeine Frage stellt und dann zunehmend technischer wird, kann das System automatisch zusätzliche technische Dokumentation nachladen und die Antworttiefe erhöhen. Diese Adaptivität erfordert eine sorgfältige Orchestrierung, liefert aber deutlich bessere Ergebnisse als ein statischer Ansatz.
Ebenso wichtig wie die Kenntnis guter Techniken ist das Bewusstsein für Anti-Patterns — also Muster, die vermieden werden sollten. Das häufigste Anti-Pattern ist der überladene Context: Wenn dem Modell so viele Informationen, Regeln und Werkzeuge zur Verfügung gestellt werden, dass es den Überblick verliert. In der Praxis zeigt sich das durch inkonsistente Antworten, ignorierte Anweisungen und erhöhte Latenzzeiten. Die Lösung ist radikale Priorisierung: Nur die Informationen bereitstellen, die für die jeweilige Aufgabe wirklich relevant sind.
Ein weiteres Anti-Pattern ist die fehlende Versionierung. Context Engineering ist ein iterativer Prozess, und ohne saubere Versionskontrolle kann nicht nachvollzogen werden, welche Änderung welche Auswirkung hatte. Professionelle Teams behandeln ihre System Prompts und Context-Konfigurationen wie Software-Code: mit Git-Versionierung, Code Reviews und automatisierten Tests. Nur so lässt sich ein Context über Monate und Jahre hinweg zuverlässig weiterentwickeln.